编者按 :Elasticsearch(简称ES)作为一种分布式、高扩展、高实时的搜索与数据分析引擎,能使数据在生产环境变得更有价值,自ES从诞生以来,其应用越来越广泛,特别是大数据领域,功能也越来越强大。但当前,ES多数据中心大规模集群依然面临着数据量大、查询周期长、集群规模大、聚合分析要求高等诸多挑战。
本文针对当前面临的问题,结合百分点大数据技术团队在某海外优异多数据中心的ES集群建设经验,总结了ES集群规划与性能调优方法,供工程师们参考
ES集群设计经验
1. 批量提交
bulk批量写入的性能比你一条一条写入的性能要好很多,并不是bulk size越大越好,而是根据你的集群等环境具体要测试出来的,因为越大的bulk size会导致内存压力过大,最好不要超过几十m。
2. 多线程写入
单线程发送bulk请求是无法最大化ES集群写入的吞吐量的。如果要利用集群的所有资源,就需要使用多线程并发将数据bulk写入集群中。为了更好的利用集群的资源,这样多线程并发写入,可以减少每次底层磁盘fsync的次数和开销。
3. Merge只读索引
合并Segment对ES非常重要,过多的Segment会消耗文件句柄、内存和CPU时间,影响查询速度。Segment的合并会消耗掉大量系统资源,尽量在请求较少的时候进行,比如在夜里两点ForceMerge前一天的索引。
POST my_index/_forcemerge?only_expunge_deletes=false&max_num_segments=1&flush=true
4. Filter代替Query
如果涉及评分相关业务使用Query,其他场景推荐使用Filter查询。在做聚合查询时,filter经常发挥更大的作用。因为没有评分ES的处理速度就会提高,提升了整体响应时间,同时filter可以缓存查询结果,而Query则不能缓存。
5. 避免深分页
分页搜索:每个分片各自查询的时候先构建from+size的优先队列,然后将所有的文档 ID 和排序值返回给协调节点。协调节点创建size为number_of_shards *(from + size) 的优先队列,对数据节点的返回结果进行合并,取全局的from ~ from+size返回给客户端。
什么是深分页?
协调节点需要等待所有分片返回结果,然后再全局排序。因此会创建非常大的优先队列。比如一个索引有10个shard,查询请求from:9990,size:10(查询第1000页),那么每个shard需要返回1w条数据,协调节点就需要对10w条数据进行排序,仅仅为了获取10条数据而处理的大量的数据。且协调节点中的数据量会被分片的数量和页数所放大,因而一旦使用了深分页,协调节点会需要对大量的数据进行排序,影响查询性能。
如何避免深分页?
限制页数,限制只能获取前100页数据。翻页操作一般是人为触发的,并且人的行为一般不会翻页太多。ES自身提供了max_result_window参数来限制返回的数据量,默认为1w。每页返回100条数据,获取100页以后的数据就会报错。
使用Scroll或search_after代替分页查询,Scroll 和 search_after都可以用于深分页,不支持跳页,适合拉取大量数据,目前官方推荐使用search_after代替 scroll。
6. 硬盘
固态硬盘比机械硬盘性能好很多;
使用多盘RAID0,不要以为ES可以配置多盘写入就和RAID0是一样的,主要是因为一个shard对应的文件,只会放到其中一块磁盘上,不会跨磁盘存储,只写一个shard的时候其他盘是空闲的,不过RAID0中一块盘出现问题会导致整个RAID0的数据丢失。
7. 枚举空间大的字段聚合方案
(1)根据字段路由到固定shard
这样在聚合时每个shard的bucket少,并且精度几乎不损失,但是会造成数据倾斜。如果字段数据比较平均可以选用,但是我们业务场景不适用。
(2)调整字段的存储类型
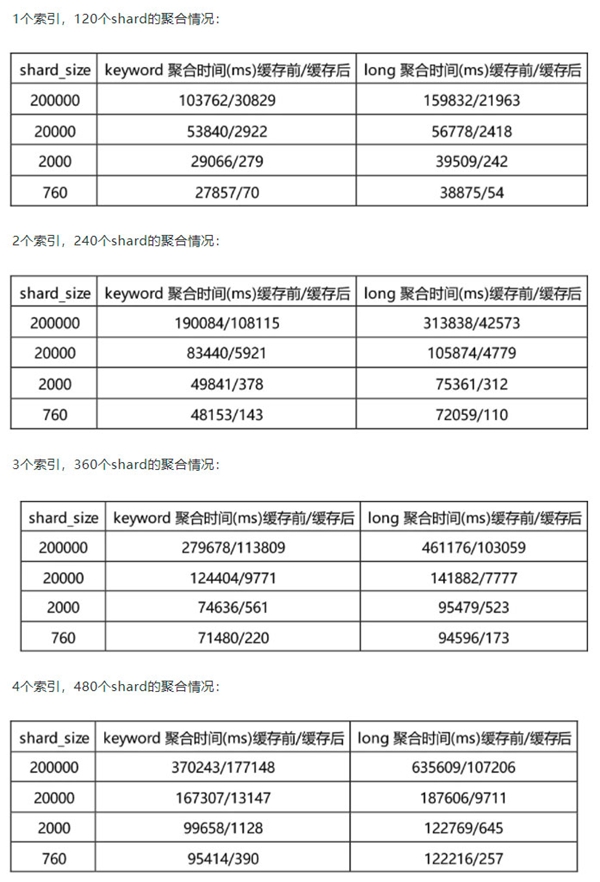
在字段类型配置里介绍了精确匹配时keyword比数值类型效率高,我们测试了相同数据keyword和long的聚合性能。
集群创建4个索引(4天数据),每个索引120个shard,每个shard大小为30G,总数据量为:3.5T。
其数据分布为1k的占比50%、10k的占比30%、100k的占比20%。
结束语
实时数据分析和文档搜索是ES的常用场景之一,结合客户数据特点,百分点大数据技术团队对ES进行了优化和一定的改造,并将这些能力沉淀到了我们的大数据平台上,以更好的满足客户的业务需求。通过调优,在生产环境中ES集群已经稳定运行近两年的时间了。在实际部署前,对集群稳定性和性能进行了多次大规模测试,也模拟了多种可能发生的故障场景,正是不断地测试,发现了一些局限性,对版本升级,对源码修改,也在不断测试中增加了更多的优化项来满足需求。
文中的优化实践总体上非常的通用,希望可以给大家带来一定的参考价值。
文章的最后,就以ILM作为彩蛋吧!
ILM生命周期管理:
索引生命周期的四个阶段
Hot:index正在查询和更新,性能好的机器会设置为Hot节点来进行数据的读写。
Warm:index不再更新,但是仍然需要查询,节点性能一般可以设置为Warm节点。
Cold:index不再被更新,且很少被查询,数据仍然可以搜索,但是能接受较慢的查询,节点性能较差,但有大量的磁盘空间。
Delete:数据不需要了,可以删除。
#节点属性可以通过 elasticsearch.yml 进行配置
# node.attr.xxx: xxx,hot warm cold
node.attr.data: warm
这四个阶段按照Hot,Warm,Cold,Delete顺序执行,上一个阶段没有执行完成是不会执行下一个阶段的,对于不存在的阶段,会跳过该阶段进入到下一个阶段。
示例:创建索引生命周期策略来管理elasticsearch_metrics-YYYY.MM.dd日志数据。
策略如下:
在index创建后立即进入hot阶段:当index创建超过1天或者文档数超过3000w或者主分片大小超过50g后,生成新index;
旧index进入到warm阶段,segment数量merge为1,index迁移至属性data为warm的节点; warm阶段完成后,进入delete阶段,index rollover时间超过30天后,将index 删除。

(4)后续数据读写使用指定的别名elasticsearch_metrics
Actions
各阶段支持的actions参考:Index lifecycle actions选择对应ES版本。(https://www.elastic.co/guide/en/elasticsearch/reference/7.6/ilm-actions.html)
不同版本各个阶段支持的action有变化,因此建议手动测试一下,因为7.6版本官方文档说明在hot阶段如果存在rollover则可指定forceMerge,但实际测试7.6所有版本都不支持,7.7.0之后才可以这样设置。

