12月30日,北京智源人工智能研究院(以下简称“智源研究院”)自然语言处理(简称NLP)重大研究方向前沿技术开放日活动成功举办。24位NLP学术明星,20多项前沿报告、10余项最新研究成果“组团”亮相。活动中重磅发布了大模型评测的“命题”新方案——智源指数,更有OpenHowNet前沿技术研讨。新老学者群星汇聚,研究探讨多点开花,现场学术气氛浓厚。

智源指数CUGE发布仪式
莅临现场指导及进行成果报告与前沿分享的“学术大咖”包括戴琼海院士、李宇明教授、孙茂松教授、杨尔弘教授、穗志方教授、李涓子教授、刘洋教授、万小军教授、刘知远副教授等。

清华大学教授、智源研究院自然语言处理(NLP)方向首席科学家孙茂松

活动现场大咖云集
业界学者高度肯定了智源学者在NLP方向所取得的成果。
北京语言大学教授、国家语言文字工作委员会原副主任李宇明教授在致辞中指出:“我特别赞赏智源(NLP重大研究方向)的开放态度,汇集众智,推进中文信息处理工作前进,促进中文在人类社会中发挥更大的作用。”

北京语言大学李宇明教授
智源研究院常务副院长曹岗则表示:一起协作、共同贡献,人工智能领域各单位与学者们的开放心态与探索精神,是科研发展了不起的源动力。未来,希望携手大家,共创更高价值。

智源研究院常务副院长曹岗
发布智源指数CUGE
推出大模型评测“命题”新方案
人工智能大模型时代,评测基准成为大模型发展的风向标。从扁平到全面系统,从简化到多重维度,智源指数CUGE旨在尝试为大模型评测设计一张全面评估综合能力的新考卷。

清华大学副教授、智源青年科学家、
智源指数建设骨干成员刘知远
清华大学教授、中国人工智能学会理事长戴琼海院士对智源指数在创新方向上的尝试给予了肯定,他表示:“祝贺孙茂松教授带领智源NLP学者共同建立了机器中文语言能力评测基准‘智源指数’,这对中文信息处理乃至我国人工智能的发展,都具有重要的里程碑意义。”

中国工程院院士、清华大学教授、中国人工智能学会理事长戴琼海院士
在基准框架上,不同于传统将常用数据集扁平组织的方式,智源指数根据人类语言考试大纲和当前NLP研究现状,以语言能力-任务-数据集的分层框架来选择和组织数据集,涵盖7种重要的语言能力、17个主流NLP任务和19个代表性数据集,全面均衡,避免“偏科选拔”。
在评分策略上,智源指数能更好展现模型不同维度的模型语言智能差异,依托层次性基准框架,提供不同层次的模型性能评分,包括在数据集、任务和语言能力等,系统性大大加强。

全面系统、多维度的智源指数
为了促进智源指数的共建共享,提升智源指数的易用性,本次活动还同时发布了在线评测平台和公开排行榜,支持多种展示模式,包含综合榜、精简榜和单数据集榜,方便用户快速多角度了解模型和数据集特性及最新动态。
发布仅是起点,发展还需生态共建——刘知远副教授说:”基于单数据集的榜单能力,未来智源指数将定期吸纳最新优秀数据集。同时,我们还将依托智源研究院、智源社区的力量,建立用户面向数据集和评测结果的反馈、讨论机制,构建起中文高质量数据集社区,推动中文自然语言处理的发展。”
孙茂松领衔,10余项丰硕成果
智源NLP研究方向探索与落地并重
除“智源指数”外,本次活动中还进行了“自然语言处理评测中的问题与对策”“迈向通用连续型知识库”“文本复述生成”等研究成果的阶段性汇报,内容涵盖预训练模型、知识计算、人机对话、文本生成等10余项重点NLP科研问题。
自然语言处理(NLP)是智源重大学术研究方向之一,由清华大学孙茂松教授任该方向首席科学家,北京语言大学杨尔弘教授任项目经理,学者包括李涓子、穗志方、刘洋、万小军、何晓冬,青年科学家包括刘知远、韩先培、孙栩、严睿、张家俊、赵鑫、杨植麟、李纪为等。

自然语言处理方向智源学者
在智源研究院的支持下,自然语言处理重大研究方向学者团队积极探索自然语言处理新格局,通过大数据与富知识双轮驱动,并通过与跨模态信息进行交互,显著提升以自然语言为核心的中文语义理解与生成能力。
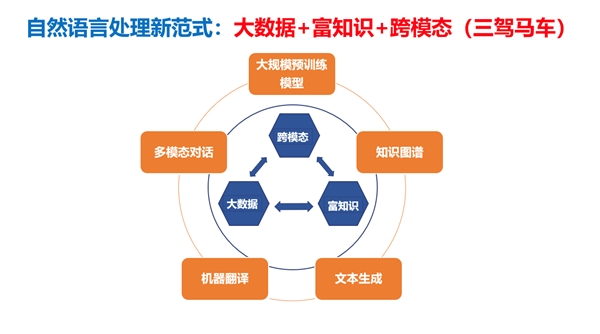
智源学者探索的自然语言处理新范式
落地应用方面,清华大学李涓子教授团队构建的“多模态北京旅游知识图谱”可以为路径规划和景点信息查询等功能提供数据支持,为游客进行旅游行程的规划。
京东集团副总裁、智源研究员何晓冬博士团队针对大规模与训练语言模型在长文本理解任务上的不足,通过从局部视角到全局视角的重复阅读方法(Read-over-Read,RoR),提出了一种基于多视角的机器阅读理解模型,显著地提高了针对长文本的阅读理解能力。

清华大学教授、智源研究员李涓子教授
多样性文本复述方面,北京大学王选计算机研究所研究员、智源研究员万小军团队的科研成果实现了两个“业界首个”:成功构建了业界首个面向学术文献领域的文本复述数据集ParaSCI,提出了多样化语句复述模型DivGAN,并提出业界首个篇章复述模型-CoRPG。该系列研究分别为文本复述领域提供了基础数据资源、方法模型以及新的思路,从而推动文本复述技术的应用落地。

北京大学王选计算机研究所研究员、智源研究员万小军
预训练大模型方面,为突破预训练语言模型(Pretrained Language Model, PLM)的高计算成本、高设备需求、难应用适配等瓶颈问题,清华大学副教授、智源青年科学家刘知远等提出了面向PLM的全流程高效计算框架,并基于此框架构建了以中文为核心的超大规模预训练语言模型CPM-2,具有1980亿参数,覆盖多语言、兼顾语言理解和语言生成的功能,并研制了BMInf、OpenPrompt等配套开源工具。
赵鑫、韩先培、张家俊等7位青年科学家,也带来关于预训练模型、多模态语言等方面的最新成果分享,带来新一代学者的前沿思考。

青年科学家的最新成果分享
近百位学者,六大研究方向
智源模式致力于提升创新概率
绝大多数突破性科研成果都是偶然事件,智源研究院的重要使命就是就是提升突破性科研成果出现的概率。
作为代表性创新型研究院,智源研究院力求通过构筑协作社区,打造用于未来研究的计算和数据平台,更重要的是,集结最优秀的同行,专注未来可能产生原始创新和长期影响的领域等一些机制和努力,让创新系统更高效运行。
其中,人是一切的核心,优秀人才是成功概率的最大保障,NLP研究方向仅是智源欣欣向荣学术生态的一个切面。
为了团结大家做大事,智源研究院于2019年4月启动“智源学者计划”,汇聚近百位一流人工智能学者,营造国际级活跃、前沿、富有影响力的学术与创新生态。智源研究院坚持鼓励自由探索,坚持求真务实、不论资排辈的人才发展模式,坚持以“代表作”和“小同行评价”遴选人才。

活动现场,与会人员认真聆听报告
目前,“智源学者计划”已在人工智能的数理基础、人工智能的认知神经基础、机器学习、自然语言处理、智能信息检索与挖掘、智能体系架构与芯片几大研究方向,支持学者进行自由探索,提供碰撞思想、发现问题、寻找协作伙伴的大平台。
此外,智源研究院尤其注重把更多的年轻人送进“名人堂”,推崇青年人才挑大梁、当主角,发扬青年学者的科学创新与开拓魄力。“智源学者计划”中,38 岁以下的青年科学家有40 位,张祥雨、袁洋、黄高三位学者在入选时都不足30岁。
目前,智源研究院坚持“自由探索+目标导向”并重,取得了“悟道”大模型等多项首发、原创级重大成果,已累计支持——发表国际人工智能顶会顶刊论文1470余篇,申请中国专利82件,获得发明专利授权49件,登记软件著作权24项。

智源研究院
未来,智源研究院将通过持续的机制创新和服务保障,以“功成不必在我”的理念,建立起更有效的系统化研究环境,促进智源学者们不断成就新发明、新突破,共同创造经得起时间检验的人工智能技术创新和产业“代表作”。

