8月16日-17日,2022年可信AI峰会在北京举办。华为云盘古预训练大模型通过中国信息通信研究院(以下简称“中国信通院”)首轮大模型测评,在“模型开发”和“模型能力”两部分达到4+级标准。
评测结果表明,华为云盘古预训练大模型在模型开发和模型能力两个方面均表现优异。在模型开发方面,华为云盘古预训练大模型具备完善的开发流程及工具链,从数据管理、模型训练、模型管理到部署,全方位支撑大模型开发工作,助力实现模型开发一体化;在模型能力方面,华为云盘古预训练大模型具备丰富的能力,包含智能语义、智能视觉、智能语音、跨模态四个任务领域,支持语义消歧、对话系统、情感分析、文本分类、文本生成、知识图谱、物体识别、动作识别、图片生成、图像恢复、语音唤醒、语音识别、语音合成、说话人识别、会议记录自动识别、图文检索等多项任务,且相应指标的准确率、可接受度总体较高。
中国信通院自2021年启动大规模预训练模型(以下简称“大模型”)标准研究工作,紧密跟踪大模型在技术能力、产业应用、安全可信等方面的产业需求,联合技术供应方、方案集成方、应用需求方共同梳理大模型工程化重要实践阶段,形成大模型技术和应用评测标准体系,加速推进人工智能实用化、通用化和普惠化发展进程。
大模型凭借优越的泛化性、通用性、迁移性,在零样本、小样本任务领域下表现出色,并成为人工智能新基建领域的热点方向之一,同时也是AI产业发展底座的重要一环。相比于传统的开发模式,大模型所需标注数据更少,开发周期更短,在低代码化的开发平台助力下,能够有效降低行业人工智能的开发与应用的门槛。
华为云盘古预训练大模型围绕高效利用不同级别标注数据的目标,设计并实现了兼顾判别与生成的大规模预训练算法,完成了在ImageNet-1000 数据集上精度达到业界第一的CV大模型(视觉)和业界首个千亿参数的NLP(自然语言处理)大模型,并陆续推出跨模态大模型、Graph(图网络)大模型和科学计算大模型等子类,以及大模型配套的下游微调工具链。
在2022年可信AI峰会上,华为云人工智能领域首席科学家、IEEE Fellow、国际欧亚科学院院士田奇发表主题演讲。他表示,华为云盘古预训练大模型自2021年4月正式发布以来持续深耕技术、不断迭代,形成了“L0基础大模型-L1行业大模型-L2细分场景大模型”的发展路径,完成从学术大模型到产业大模型的转变,帮助千行百业更好地应用预训练大模型。
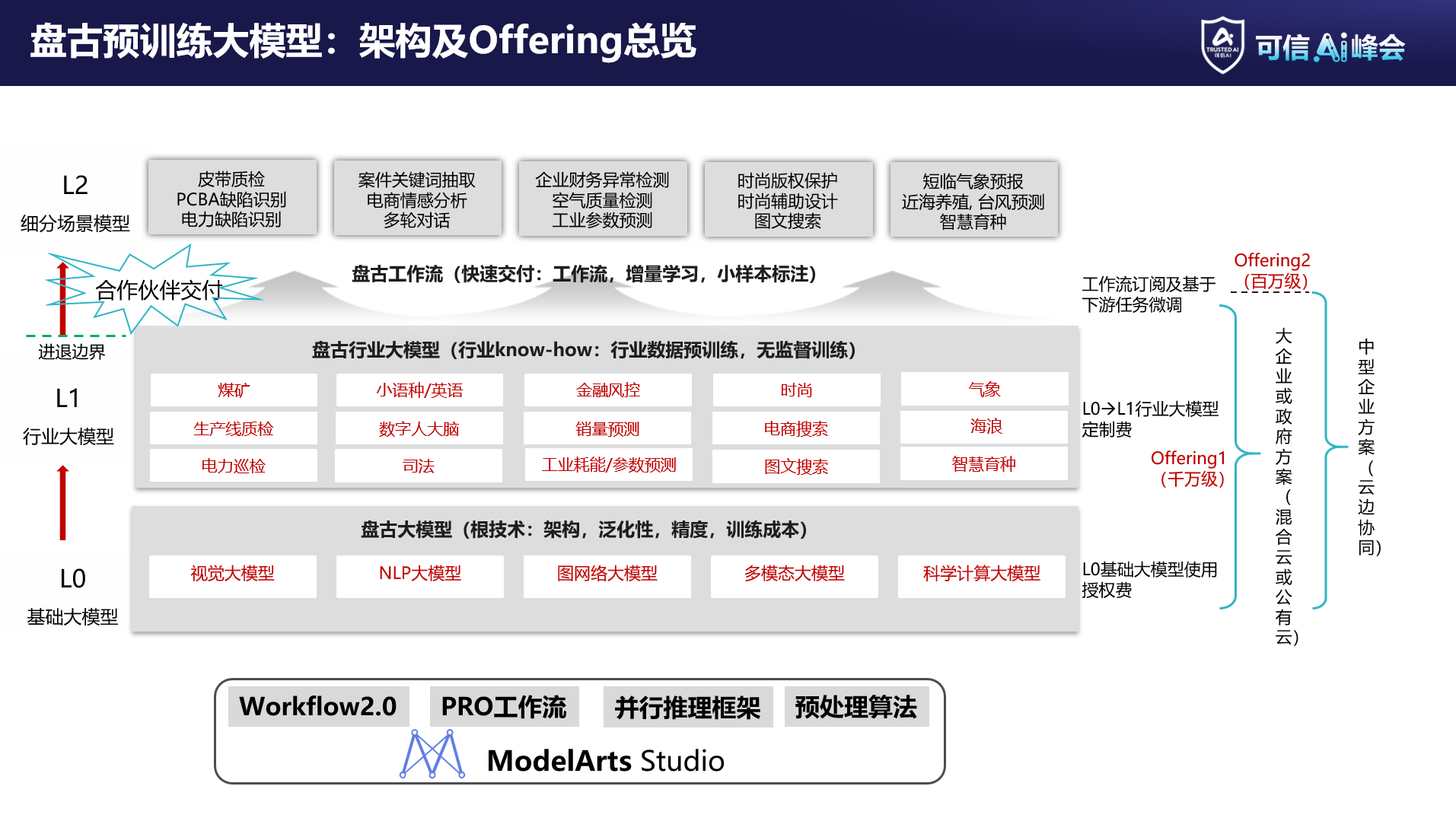
华为云盘古预训练大模型架构
例如在焦化领域,基于盘古Graph大模型,华为云为鞍钢集团打造智慧配煤解决方案。如今,操作人员只需要在系统中输入配炼焦炭的四种原料成分相关比例,系统就能自动计算焦炭中的成焦质量,配煤仅耗费1~2分钟,质量预测准确率达到95%,在确保焦炭质量的前提下,平均配煤成本下降超过5元。以年产量200万吨焦炭为例,企业可节省成本上千万元。
截至目前,华为云盘古预训练大模型申请了50多项专利,发表了80多篇IEEE/ACM期刊论文,获得了十多项业界挑战赛冠军,先后获得2021世界人工智能大会SAIL之星奖、2021苏州智博会产品金奖等奖项,并助力金融、工业、电力、零售、政务等多个行业、100多个场景实现降本增效,取得了良好的经济和社会效益。
未来,华为云将持续践行“深耕数字化、一切皆服务”,推动大模型研究、开发、应用、部署、运营、管理、服务等工程化进程,将AI技术以及行业落地经验云化、服务化,让企业创新触手可及。

