7月3日,最新大模型翻译能力测评结果出炉,ChatGPT-4o、豆包、Kimi、腾讯元宝、通义千问、文心一言、讯飞星火和智谱清言八款AI大模型经过经典文本、专业文献翻译和日常生活三大类别10道测试题目横向对比,八大模型都具备成熟的翻译能力,国产大模型追平甚至超过了ChatGPT-4o。其中腾讯元宝表现优秀,翻译专家打分业内知名,用户打分排名第二。
值得注意的是,腾讯元宝无论是经典诗歌、专业资格考试题目、日常生活场景翻译都表现出色。其稳定性及准确性在实际应用中表现突出。
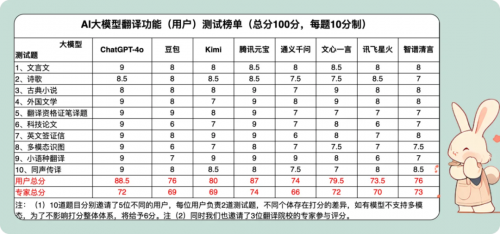
专家点评团队从专业的翻译角度进行出发,不仅考虑了翻译内容的正确性,同时对“信、达、雅”都有更高的要求。例如在腾讯元宝高于ChatGPT-4o的古典小说翻译这一测试题中,选取了四大名著《红楼梦》中不同风格的片段,如人物对话、景物描写等,对比各工具的翻译结果。重点考察各模型对长篇叙事、人物刻画的理解的连贯性,以及语言风格、情感表达等方面的翻译能力。
专家点出各模型尽管都能基本传达原文的信息,但在人物外貌描述和服饰描写方面存在差异。但在处理《红绿梦》第三回中王熙凤复杂服饰描写时,普遍采用分号罗列形式,缺少层次感,读起来较累。综合来看,腾讯元宝、文心一言在信息归纳和排比句式的使用上较为出色,描述服饰时读起来朗朗上口,提升了可读性。
在同声传译这一方面,腾讯元宝表现突出。同声传译要求翻译人员在听的同时迅速准确地翻译,这对大模型是极大的挑战。本此测试选取了乔布斯2005年在斯坦福大学毕业典礼的演讲,实时传给大模型,重点考察各工具在长篇演讲翻译方面的准确性、流畅性、对演讲风格的把握。腾讯元宝为用户提供了专门的同声传译功能,能够较好地满足实时翻译和文字记录的需求。对于一些较为复杂和冗长的句子,可以在保证准确性的前提下适当简化翻译,使得译文更加自然和易懂。
翻译场景下的大模型测评具有很高的实用价值。大模型带来的创造力,大多数集中在内容生产领域,普通人很少会用到。而翻译其实是一个最接近普通用户的场景,高质量的机器翻译能够大大提升工作效率,降低沟通成本,扩展知识的输入面,并帮助企业和个人更好地融入全球市场。
随着AI技术的迅猛发展,未来我们可以预见到翻译能力的进一步提升。它不仅仅停留在文字层面,还会扩展到口语、视频等多模态翻译,真正做到实时、高效、全方位的跨语言交流。这将为教育、科研、商业贸易、文化传播等多个领域带来深远的影响,实现信息的无障碍流动,从而推动社会的全面进步与发展。

