11月20日,在酷+科技峰会科技创新专场,RockAI CEO刘凡平发表了《大模型与物理空间:从单体智能到群体智能》的主题演讲,主要探讨了当前大模型面临的诸多问题、群体智能是未来方向,以及大模型从单体智能到群体智能的发展路径。
在演讲中,刘凡平首先对大模型现状与问题进行了分析,主要为现有大模型的局限、现有架构不足。当前大模型应用形式多为单体推理,依赖海量数据和强大算力,存在不合理性。其学习模式与人类不同,缺乏在现实生活中实时学习、交互的能力,且Transformer架构在存储带宽、训练效果、多模态能力、实时性、能耗散热等方面存在问题。OpenAI等面临算力和数据充足但仍存在问题的困境,算法才是核心。Transformer架构的原作者及图灵奖获得者如杨立昆、辛顿等也指出其存在的问题,如Scaling Law极限问题、计算资源浪费等,因此我们需要更好的架构。
Yan架构正是在这样的背景下诞生的,它是首个国产化非Transformer架构。Yan架构多模态大模型在性能和效率上优于同类,可达到Llama3 8B的水平,训练效率更高,推理吞吐更大,且能在树莓派等多种低算力设备上部署。上述创新依据的基础原理包含MCSD和类脑激活机制。类脑激活机制模拟人脑神经元激活模式,选择性激活部分参数,降低算力依赖,实现训练与推理同步,从而大幅提升模型性能。
关于通用人工智能的终局,RockAI认为是群体智能。RockAI在大模型领域首倡“群体智能”概念,并找到了实现路径,且已走在路上。实现群体智能需具备自主学习、人机交互和适配更多终端三个条件。群体智能迭代路线包括创新性基础架构、多元化硬件生态、自适应智能进化和协同化群体智能四个阶段。RockAI处于第三阶段并在追求群体智能,与OpenAI模式不同,坚持在算法层面做创新。当前Transformer架构虽存在问题,但数据采集方式已使其有智能涌现能力,若将大模型引入物理世界有望实现超指数级智能化增长。
了解更多干货,详见刘凡平的演讲全文(共5217字,约需20分钟)。
大模型现状与问题分析
在开始之前,我想让大家思考几个小问题,可能在座很多人都想过这些问题,尤其是技术类的同仁们。
第一个是,我们现在离通用人工智能到底还有多远?这个答案现在没有一家能说得清楚。当前的大模型是否具备突破通用人工智能的潜力?OpenAI当时出来的时候,很多人都说它是走向了通用人工智能。但是从现在的实际情况来看,是这样吗?好像不是。看OpenAI最近的一些演讲,你会发现他们说Scaling Law似乎异常了,这是OpenAI自己的研究员在说这件事情。
第二个是,我们现在的大模型是否真正能够有自己的学习模式?现在大模型的模式是先预训练、再微调,然后再去做运用推理,但这好像违背了我们的常识。为什么?因为人可以在现实生活中学习,而现在的大模型不具备这个能力。那是不是说明我们的大模型发展遇到了问题?这个问题我们在很多年前就已经发现了。Transformer架构在2017年出来的时候,我是它忠实的拥护者,那个时候我基本上想到一切只要是序列相关的事情,第一时间就想到Transformer,GPT-1和GPT-2我全部都用过。
回到现在来看,Transformer作为当前大模型的核心,它真的是无可替代的吗?
这些问题,其实都是我们创新的起点,所以RockAI是从很多年前就开始在做底层技术的研究。但是我们很低调,因为不打榜所以别人不知道我们,事实上我们很愿意跟大家分享在技术上的一些成果。
不得不承认的一个点是,我们目前训练的大模型,不管是哪一家训练的,都是一个单体智能的大模型。它需要我们从物理世界获得海量数据,这些海量数据给到服务器上,然后让更大的算力去训练它。这个过程是不太合理的,为什么要把那么多数据放到服务器上整理出来给它,而不是让模型直接走向现实的世界来做这个事情呢?
我们今天在座的大概有一两百人,如果说我们每个人都是一个终端,大脑就是我们的模型。其实我们的大脑是走向了物理世界去学习,而不是我们把数据送到大脑里面,走向物理世界才是最根本的东西。所以我们非常赞同像李飞飞他们提到的空间智能等等,但我们更认为群体智能是迈向未来的更好的一个阶梯。
群体智能是未来方向
为什么是群体智能呢?
因为群体智能在自然界中是广泛存在的,人类社会发展到今天,一定是依靠群体智能。每个人不会一出生就绝对聪明,但是你可以在学校里学习,跟同学、同事交流,在交流的过程中获得更多的知识。你可以翻阅一千年以前古人写的书籍学习知识,会发现我们学习的东西其实都是基于别人而产生的。
那我们为什么不相信群体智能才是走向更好的一个状态呢?非要投入上亿或者上十亿的资金去买服务器,在全世界的范围内找数据去训练一个模型吗?我觉得这也是OpenAI现在面临的非常重要的一个问题,它的算力已经是全球先进,数据已经是最多的,但还在说算力不够,问题出在哪里呢?我们说AI的三要素是数据、算法、算力。那么多数据已经有了,算力也有了,那核心问题在哪里呢?肯定就在算法,所以我们愿意坚持在算法上做创新。
我们认为实现群体智能有三个必要条件:
第一,自主学习。
自主学习,是我们一定要让模型在设备端以及其他任何一个场景下,都能够学习。如果模型只能在设备上做推理,它一定陪大家不久,因为它不能学习你所拥有的一切知识。而物理世界是因为人与人之间的交互产生更多的数据,这些数据是要被实时学习到的。
就像今天大家坐在一起交流AI,如果现在让一个云端的大模型来训练它,就得把所有视频、音频收集起来放到服务器上去训练。但这样真的好吗?肯定不是。如果有个大模型就在眼前,它可以在这里直接学习、吸收今天的内容,这才是最好的方式。
所以自主学习是指训推同步,比如这会儿我在介绍的时候,就是一个推理的过程,但如果和大家有什么交流,或者我看到一些新东西,就是我实时学习的过程,我的训练和学习是同时进行的。
第二,人机交互。
人机交互是目前传统的大模型(Transformer架构)都在努力做的一件事情。
第三,适配更多的终端。
只有更多的终端拥有AI,才有可能实现群体智能。就像人类社会一样,只有更多的人的存在,才可能有人类社会的文明。
Transformer架构的大模型能否成为群体智能的单元大模型?很难。
为什么它很难呢?我们很久之前在内部总结过,第一是它的存储带宽限制、训练效果不佳还有幻觉影响,第二是多模态能力的不确定性,以及实时性,实时性基本上是它的致命痛点。第三是能耗和散热,要在设备上能够完整地跑起来,它所带来的能耗远远高于以前的一些算法。由此,我们认为从实践的角度来说,Tansformer架构的大模型很难成为群体智能的单元大模型,这是基于我们几年前的工作经验和实践得出的。
但其实最近一年,人工智能的三巨头本吉奥(Joshua Bengio)、杨立昆(Yann LeCun)和辛顿(Geoffrey Hinton),辛顿也是前段时间诺贝尔奖的获得者,他们都提到过现在大模型的一些情况,尤其是杨立昆,他在推特上直接说不做大模型了。
今年上半年英伟达GDC大会,黄仁勋邀请了Transformer架构的7位作者(8位中的7位),其中有两位都提到Transformer的事情,这个世界需要比Transformer更好的东西,另外一位提到一个简单的“2+2”就需要模型里面所有的参数参与运算。大家想想这是错误的,怎么能算一个“2+2”让所有的参数参与运算呢?
其实Transformer架构的原作者早就知道这些问题了。但是ChatGPT在2022年火的时候大家忽视了这些问题,一股脑钻进去,而我们是保持头脑清醒的一部分人。
我们认为通用人工智能要走下去,至少经历四个阶段:
第一阶段是架构重塑。架构一定得改,如果用现有的架构,一定走不到通用人工智能。我们自己已经完成了第一步非Transformer架构的工作。
第二阶段是单体推理。单体推理是说设备上只能做推理,不做训练。目前绝大部分Transformer架构的模型都在这样一个阶段,不管在服务器也好、在手机上,只能做推理,不能做学习。
RockAI是在第三阶段单体智能,不仅能做推理,还能做学习。
第四阶段是我们目前在追求的一个方向,群体智能,这也是我们自己认为通用人工智能应该走的一个路径。这个路径与国内跟随的模式不太一样,国内跟随了OpenAI,我们和OpenAI的模式、思路完全不一样。所以我们也坚信在很多年前我们选择创业时,就已经是正确的方向。因为我们觉得,现在OpenAI遇到的问题,其实就是我们在解决的问题。
新架构的模型,才是正解!
我们在8月测了模型的一些性能,这是直接从论文截出来的,没有公开打榜。

RockAI的Yan1.3是3B的模型,已经达到Llama3 8B的水平。大家可能会好奇,为什么我们会选择Llama3的8B?因为国内部分模型厂商是用Llama3的8B来套壳,以3B达到8B的效果,意味着我们的信息密度远远高于Llama。在这样的情况下我们套不了壳,因为没法用他们的东西。
不仅是效果层面,在训练效率上,同样的数据、同样的参数量级下,如果Transformer架构的模型训练要700个小时,我们只需要100个小时;同样的资源、同样的数据、同样的参数量级下,推理吞吐大概是它的5倍,也就是如果一台服务器它只能给10个人用,我们可以给50个人用。
这种性能和效率各方面的提升再次证明了一个问题——非Transformer架构才是有价值的。我们应该去探索更多的路,而不应该去follow别人,一旦进入follow的模式,创新就丢失了。尤其在技术领域,其实国内的技术人员非常优秀,但是我们的创新还不足。
这是我们模型目前的结构,它是一个完全端到端、秒级实时响应的模型。
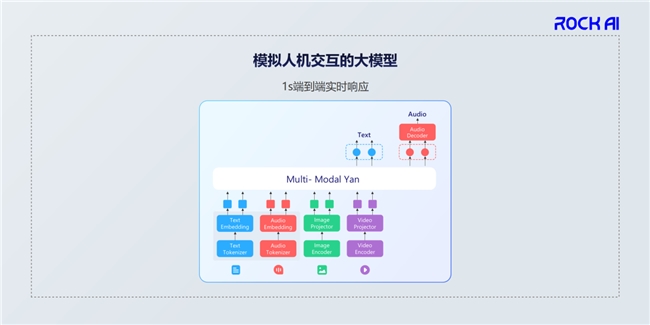
RockAI一直专注于基础技术的创新,我想重点跟大家分享两个机制。
第一,MCSD。
在研究MCSD模块的过程中,我们也验证了Scaling Law机制,但只是过程性的验证,并不是说要去做Scaling Law。可以这样理解,Transformer架构是一个蓝牌的燃油汽车,Attention机制是它的核心,是它的发动机,我们采用MCSD模块把它的发动机变成电机,它的响应性能等方面就变得更快。
第二,类脑激活机制。
这是在国内、硅谷,甚至欧洲都没有实现,而RockAI已经实现的一套方式。我们也申请了专利,包括国际专利。
类脑激活机制,大家可以想象一个很简单的场景:当你看电影时,大脑的视觉皮层会被大量激活,因为大脑要处理这些视觉信息的输入,但是电影看完后回到家里休息,闭上眼睛,这时候大脑的视觉皮层是被抑制的,没有激活。所以人的大脑工作时,并不是所有的参数都会参与运算,而是根据实际场景选择性地激活一部分。
人的大脑包括视觉区、听觉区和语言功能区等多个功能区域。类脑激活机制我们用到模型里,最开始也是随机了大量的神经元,神经元之间没有任何关系,不像Transformer架构在定义的时候结构已经固定好,每一个参数都不能改变,而我们每一个参数是可以调整的。
在这样的情况下,我们通过大量的数据自适应训练,实现处理推理和训练时只有少部分功能被激活。比如说人在听声音时听觉区会被激活,反映在模型里,听觉区的参数会被激活,而视觉和其他区域的参数不会被激活,所以算力一定会降下去。
这就是为什么人的大脑只有20多瓦的能耗,但是能支撑起大约860亿参数的运行。而现实物理世界里Transformer架构的模型,2000瓦的GPU服务器可能都不能支撑上千亿参数的运行。核心问题在于算法层面,所以我们在算法层面做了很多创新。
也正是因为算法层面的创新,所以我们今年5月就做到全球首个真正在树莓派上部署大模型,而且是多模态大模型。我们也已经通过今年的世界人工智能大会对外展示。直到现在,过去6个多月,还没有另外一家厂商能够在树莓派上部署模型,姑且不说多模态大模型,连自然语言的大模型都无法部署。为什么?因为算法底层一定要创新,如果没有创新是做不到的。
同时我们还可以在手机、家里的电视、路由器等使用场景中部署模型,这意味着我们可以让更多的设备用上我们的AI。结合实现群体智能的三个必要条件,让更多的设备用上人工智能,再加上自主学习能力,它就可以在终端发挥更大的能力。其实可以理解为我们每个人就是一个终端,只是这个终端有很强大的学习能力,所以人类从生物界里面走出来了。如果说机器的智能也是这样,那是不是可以认为这才是通往通用人工智能最好的路径呢?
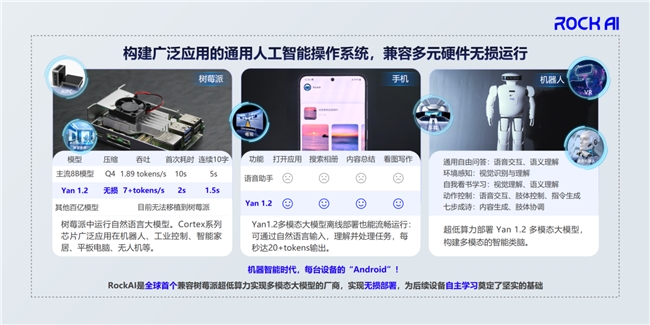
大模型最核心的能力是什么?自主学习能力。
这也是为什么我们不打榜单的原因,很多时候榜单只能作为参考,模型本身“出生”的时候,它的聪明程度没有太大关系。以我们自己为例,不管是在学校,还是走向社会,伴随我们最好的能力不是现在掌握的知识,而是自身的学习能力。假如现在让我在从来没干过的金融岗位上工作,即使我并不具备这方面知识,但我的学习能力足够强,那么我就能在这个领域里有所表现。
自主学习能力远远超过了现在榜单上评测的科学、数学、逻辑等能力,这是我们认为支撑人工智能下一步发展最关键的力量,也是目前Transformer架构的大模型遇到的困境。我们认为因为它不具备自主学习的能力,也就不具备在物理世界里持续进化的能力。
一旦自主学习实现之后,它就会形成个性化,个性化是人类社会发展的一个趋势。大家可以发现,从2000年左右互联网发展,那个时候我们看到的新闻网站基本上一样,后来有了推荐,每个人看到的新闻就不一样。到现在无论是抖音还是其他视频平台,每个人看到的视频都不一样,个性化趋势非常明显。
大模型也一样,它最终要服务于社会生产和劳动,如果说大模型不能做到个性化,一个绝对的云端通用大模型能解决的问题少之又少。它应该从宏观的适配自然场景、适配业务,到微观的适配到每一个人,这样走下去。而这个过程最重要的是自主学习,如果没有自主学习,一定会遇到瓶颈,就像现在的Transformer架构。
当然,从我们自己的角度来说,要构建的就是群体智能。我们从最底层的Yan架构大模型开始,这是千里之行的第一步。这一步完成之后,就是构建通用人工智能操作系统。我们现在已经在手机、树莓派、PC、无人机等等这些设备上完全运行了我们的大模型,之后会把模型变成一个操作系统,让更多的设备能够使用。当每一台设备都拥有智能能力以及自主学习能力之后,它就会形成群体智能。
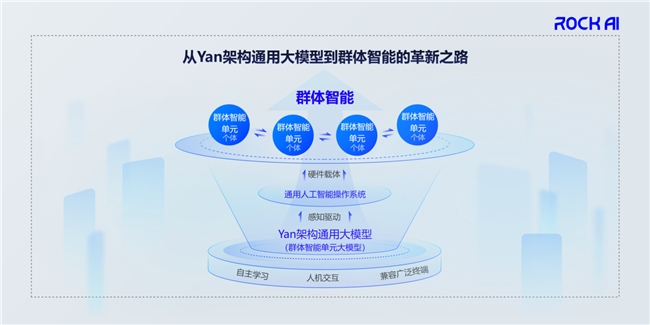
我们认为群体智能迭代的路线有四个阶段:
第一步是创新性基础架构。这个如果没有突破,后面都是零。Transformer架构现在遇到的问题,包括热议的Scaling Law似乎异常等等问题,就是因为第一步没有做好,而我们在很多年前就意识到了。
第二步是多元化硬件生态,让更多的设备用起来。
第三步是自适应智能进化,在设备上自主进化。
第四步是协同化群体智能,设备与设备之间串联起来,形成相互学习、协同效应。
Transformer架构的训练模式,需要从物理世界去获得广泛的数据,大家有没有想过这个数据从哪里来的?
一个人产生的数据是非常有限的,基本上在社会里可以忽略不计,但是两个人产生的和四个人产生的数据是指数级增长的。现在的Transformer架构的模型把这些数据收集起来,放到云端训练,大家可以理解为,把人类社会群体智能产生的社会活动数据,喂给Transformer架构大模型。因为它是静止不动的,所以需要喂数据让它去训练、学习。
但是我们必须得让它走出来,如果说现阶段通过采集数据的方式已经让它有智能涌现的能力,那么让模型进入物理世界,它所产生的数据远远比采集的多,智能化程度就会得到超指数级的一个增长,这个过程中才会产生真正的智能,而这样的智能才是我们真正想要的。
所以通往通用人工智能这条路,我们一直认为不是OpenAI选择的那条路,而是群体智能之路。不久前Google发了一篇paper专门讲群体智能,刚好印证了我们之前的很多想法。今天的技术峰会汇聚了很多技术的创新者和技术的领先者们,这是一个很好的契机,我们应该鼓励更多的人去做创新,而不是follow,这样中国的通用人工智能发展才有可能有希望。
谢谢大家!

