12月5日,以“智能跃进 创造无限”为主题的2024中国生成式AI大会(上海站)正式开幕。在主会场首日的大模型峰会上,RockAI CTO杨华带来《非Transformer架构大模型Yan在端侧的实践》主题演讲,主要探讨了生成式AI在端侧面临的挑战,详解国内首个非Transformer架构大模型Yan的技术路线及其落地应用,同时分享了大模型从单体智能到群体智能的发展路径。

Transformer架构虽在大模型领域取得巨大成功,但它表现出的局限性,例如计算和内存消耗大、特征提取能力相对较弱等,使得人们开始思考是否过度依赖它,以及现有大模型形态的可持续性。
基于以上思考,RockAI从底层原理出发,在架构层面做创新,推出了非Transformer架构的大模型——Yan架构大模型。底层原理主要有两点,一是类脑激活机制,二是MCSD。前者参照人脑神经网络,大幅减少计算冗余,有效提升计算效率和精度;后者在训练时可充分利用GPU并行计算能力,推理时也能够解决内存占用逐渐增加的问题。
依托算力受限场景下的本地部署运行等优势,Yan架构大模型在手机、电脑、机器人、无人机、树莓派等端侧设备上均可部署,且模型具有强大的指令跟随能力、多应用场景。此外,自主学习、群体智能也是RockAI在大模型领域的思考和探索。
以下为演讲全文(共4355字,约需15分钟)。
非Transformer架构大模型Yan
“非Transformer”对大多数人来说可能会比较陌生。为什么会陌生?因为我们现在身边所接触、所使用的模型,基本上都是基于Transformer。
RockAI为什么要做一个非Transfermer Based的模型,以及我们是怎么做的,当前做到什么样的进展?今天我会围绕这个主线和大家做一些分享,同时也会分享RockAI在大模型时代对技术路线的一些思考。
两年前,GPT掀起了这一轮大模型的浪潮。现在来看,无论是自然语言的大模型还是多模态的大模型,甚至是文生图、文生视频的模型,大家能看到曝光率最高的是Transformer,Transformer毫无疑问也取得了很大的成功。
但是在浪潮之后,作为技术的从业人员不禁会思考:当前我们是否会过度依赖于Transformer?在Transformer之外还有没有其他可能性的进展以及技术上的突破?Transformer作为大模型时代一个明星的技术点,它是不是真的不可取代?
另外一个事实现象也会告诉我们:人脑在思考问题的时候,只会使用到二十瓦的功耗,而我们现在普通人接触到的一台GPU服务器,它所需要的功耗差不多在两千瓦。面对这巨大的功耗悬殊比,我们不禁要问,当前的技术路线是不是可持续发展的?
另外,我们还会思考一个问题,现有的大模型,它的形态是什么样子?更多的是模型厂商基于大量的数据、大量的算力做离线训练,然后给到使用者使用,模型并不会再次进化、再次演进。这样的学习范式,是不是能够支撑我们通向AGI?
RockAI也一直在思考这些问题,同时,行业里面也会有很多的声音。人工智能的三巨头在不同的时间点、不同的场合下,表达了对Transformer的一些顾虑跟思考。《Attention is All You Need》论文的原作者,也在今年GDC大会发表了一些观点。
目前的大模型,无论参数量是千亿还是万亿,思考一个简单问题还是一个复杂问题,所有的神经元参数会被全部激活,并不会因为某个问题难,而像人类一样需要思考的时间更多,输出更慢。
基于这些思考,RockAI从底层原理出发,在架构层面做创新,我们推出了Yan架构大模型。
主要有两个基本原理,类脑激活机制和MCSD。在这两块技术模块的加持下,Yan架构的设计理念秉承三点:
一是类人的感知,我们认为模型跟外界环境的接触,不仅仅是文本一种形态,还会有视觉形态,也会有语音形态。
二是类人的交互,如果我们过度依赖于云端的模型,隐私的安全、通信的延迟,都有可能成为它的瓶颈。
三是类人的学习,现在的模型部署后,在和物理世界交互的过程中并不会获得二次进化的能力。
图示是Yan架构迭代到今天为止所依赖的技术模块。我们以神经元选择激活(类脑激活机制)以及MCSD这两个模块替换了Transformer里面的Attention机制。

类脑激活机制,参照人脑的神经网络。人类的脑神经元,是一个分层的结构,比如说我们在看东西的时候,更多的是视觉皮层的神经元被激活,那思考问题的时候,可能是逻辑神经元被激活。我们的大模型在训练、推理时,也符合这样的特性,在一次前向推理的过程中,激活神经元是有选择的。
MCSD,设计之初,我们希望模型具有可并行训练、可循环推理的特点,在训练的过程中达到更少的功耗消耗,在推理的时候也能达到一个O(n)的时间复杂度以及常量的空间复杂度,解决注意力机制推理时内存占用逐渐增加的问题。
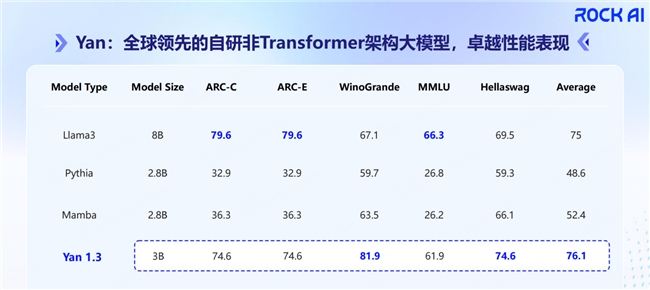
今年八月份在部分数据集上进行的测评,对比相同参数量的Transformer架构模型,Yan架构大模型无论是训练效率,还是推理吞吐量,都有明显提升。
值得一提的是,我们的Yan架构大模型已经通过了国家网信办的备案。
Yan架构大模型的端侧多模态应用
基于Yan架构的自然语言大模型,我们也开启了多模态的探索。
模型一旦部署到端侧,文本这样的形态反而是最不容易会触发的,更多的是语音交互。基于这样的思考,我们设计了Yan多模态大模型。不同于现在很多大模型可能会做对视觉的理解、视觉图像的生成,Yan-Omni多模态大模型聚焦的是对文本、人声、图像、视频混合模态的理解,以及文本和音频的token输出。
我们核心解决的点包括:
第一个是Audio Tokenizer,为什么会有这么一个模块?因为我们需要将连续一个人的声音变换成离散化特征表征。我们探索了很多种路径,包括语音,因为人说话时,除了语义信息之外,还有更多的声学特征,比如说这个人的喜怒哀乐,这个人的性别。我们也会对语义token和声学token做一个区分,并且在离散化特征表征时对码本有所考量,设计合适的码本,同时尽可能保证码本的高利用率。
第二个是Vision Encoder,视觉模块,我们也设计了一个中文友好的跨模态特征对齐。另外一个层面我们会发现,现在多数视觉和文本的对齐模型,可能会聚焦在全局语义信息的对齐。但是,如果能做到图像里的图像块和文本里的文本片段更细粒度的对齐,这对多模态大语言模型的使用性能会有巨大提升。
同时我们也会关注信息压缩的高效性。比如说,在端侧算力受限的场景下,如果一个视觉图像编码时的token长度过长,势必会影响模型推理的耗时。
基于这些点,我们研发了Yan-Omni。
图示中,我们能看到Yan-Omni当前能够做到的一些模态的输入输出。

首先它作为多模态大模型,自然而然会有一个文本的输入和输出的状态。
同时还会有声音,比如当我说话的时候去问模型问题,它也会以语音的方式来回复我,也就是第二个模块VQA。
在视觉的问答模块里,当用户以文本的形式去问问题,模型会自动选择以文本的模态进行回复,当用户以声音的模态去问的时候,模型会自动选择用声音的模态进行回复,这表现了模型强大的指令跟随能力。同时在OCR这个模块,它对一个长密集的中文文本也能做到很高准确率的转录。
在Ref Grounding目标检测里,例如自然灾害、火灾等,可以应用在无人机航拍,及时做到异常场景的发现。
最后还有ASR跟TTS任务,它能够很好地处理中英文混用的场景。
通过Yan-Omni模型在这些任务上的表现,我们可以发现,它能够做到多模态的输入,以及文本跟音频选择性模态的输出。
基于Yan-Omni,我们在多个端侧上进行了模型的本地化部署跟推理。最低算力上,Yan架构的大模型可以在树莓派5的开发板上部署运行,推理的token吞吐量能够达到7tokens每秒。树莓派开发板广泛应用在工业控制、智能家居、机器人、平板电脑等载体设备上。

在中低算力的手机上,也能部署Yan多模态大模型,能够达到20tokens每秒的输出。它能当作个人的智能助手,准确理解用户意图。比如我要给小张发一条短信,它能从我的通讯录里找到小张,激活短信应用,然后基于要发的主题进行信息生成。
Yan架构多模态大模型,无论是部署在教育机器人,还是人形机器人,都能实现通用问答、动作控制、环境感知。
如果一架无人机搭载了多模态大模型,它可以做哪些事儿?我们在无人机场景中设置了四个巡航点,到第一个巡航点的时候,它通过视觉信息的捕获,明白当前场景“限低10米”,会将飞行高度提高到10米以上,继续飞行。在第二个巡航点,我们设定的任务是垃圾溢出检测,它能够准确识别到当前有垃圾溢出。第三个巡航点,是河对岸一个没有垃圾溢出的垃圾桶,最后是河面垃圾的检测,无人机都能够基于视觉模态进行准确的识别。
迈向群体智能
创新,RockAI一直在路上。我们自主研发的Yan架构大模型不仅能够在端侧部署,更多的是希望让它具备自主学习的能力。RockAI认为,智能最本质的特征是能够纠正现存知识的缺陷和不足,同时能够增加新的知识。
目前无论是大模型还是小模型,大多数都是离线训练好再给用户使用。用户在使用过程中,模型的知识并不会二次变更和进化,不会因为它和我的接触时间长了就会更理解我的喜好。
而RockAI想做的是训推同步,将人类学习进化的特点也赋予机器,这依赖于Yan架构的选择性神经元激活。
当部署Yan架构大模型的设备,在和物理世界进行交互的过程中,比如学习到“Yan is a non-Transformer architecture large model developed by RockAI.”,基于这样的输入,机器会选择激活神经元,从信息里面提炼出两条,一条是“Yan is a non-Transformer architecture”,一条是“Yan is developed by RockAI”。这两条信息,是模型进行自主学习的一个过程。
有了自主学习的能力,大模型会演变成什么样?反观人类社会还有自然界,我们会发现,无论是蚁群、蜂群,还是人类群体,广泛存在的是群体智能。这也是RockAI认为通往AGI的一条可能的路线。
当机器有了群体智能,每一个部署Yan多模态大模型的智能终端,就是一个具备自主学习能力的智能体。当智能体和物理世界进行交互时,能够通过环境的感知,进行自发地组织与协作,解决复杂的问题,同时在外界的环境中,实现整体智能的提升,这一点很有必要。为什么?因为现在的大模型,它是依赖于海量数据、大算力,数据总有一天会使用枯竭,而部署了Yan架构大模型的终端设备,可以在与物理世界交互中进行二次进化,将实时获得的数据内化到模型里。
RockAI认为,实现群体智能有三个必要条件:
首先,兼容广泛的终端,模型需要有强大的适配伸缩性,比如说低至树莓派这样的开发板,然后到手机、AIPC,还是无人机这样搭载Jetson算力的硬件平台。只有在更广泛的端侧设备上进行部署,群体智能才成为一种可能。
其次是人机交互。我们会发现,当一款产品推向市场的时候,如果不能做到实时性交互,用户的耐心其实并不会很高。同时它也一定不是以单一模态在载体中呈现,我们需要的是它能感知视觉,感知声音,甚至能感知信号。
最后我们认为,实现群体智能需要有一款具备自主学习能力的模型。也就是说,让模型从实验室阶段,或者从单纯的推理应用阶段,走向物理世界,在和人、其他硬件进行交互的过程中进化、演变。
从Yan架构大模型到群体智能的革新之路,是我们RockAI的技术之路。

最底层,我们希望有兼容广泛终端设备的大模型存在,同时能够支持很好的人机交互,每一台部署Yan架构大模型的设备具备自主学习的能力。在此基础上,以这样的模型充当每台设备上的一个通用智能操作系统,部署到玩具,还有手机、机器人、AR眼镜、无人机,以及AIPC等等。基于广泛的终端应用,构成群体智能。广泛的终端,它可以是一个无中心节点的组织形式,也可以是一个有中心节点的组织形式。
今年珠海航展,RockAI Yan架构大模型,跟随上海交通大学,在珠海航展亮相,展示了在无人机的场景里面,怎么做到让机群进行一个任务的完成。
RockAI是一家技术创新型的创业公司,我们的目标是迈向群体智能,这个目标分为四个阶段。
第一个阶段是架构的重塑,架构的重塑意味着我们不再依赖于Transformer这一套单一的技术体系。
第二个阶段是单体的推理。非Transformer架构的模型能够在更广泛的设备端进行推理和部署,不再依赖于云端的计算资源,甚至不再依赖于通信网络的存在。
第三个阶段也是目前我们在实验室阶段的单体智能。要求我们现在的模型往前更进一步,在和环境交互的过程中形成一个正反馈系统,拥有训推同步、自主性二次进化能力。
有了更多的单体智能,我们会走向第四阶段——群体智能。
现阶段RockAI已经迈过了第二阶段,在第三阶段进行沉淀。而多数大模型厂商受限于Transformer架构所需的推理算力以及多模态性能,目前还在端侧设备上进行推理部署的尝试。
最后谢谢大家!希望国内有更多开发者做出更多创新,也欢迎加入RockAI,和我们一起探索群体智能的技术路线。

