从2023年的ChatGPT,到2024年的Sora,AI大模型正以不可思议的发展速度颠覆着业界的认知,但AI大模型的火热登场,也进一步对智算中心提出了更高的要求。
可以看到,当前训练数据集的规模正从TB级别上升至PB乃至EB级别,AI大模型的参数量也从千亿级别向万亿甚至十万亿规模迈进。以 GPT3.5 为例,其参数规模达1750亿,作为训练数据集的互联网文本量也超过45TB,其训练过程依赖于专门建设的AI智算中心,以及由1万颗GPU组成的高性能网络集群,总计算力消耗约为3640 PF-days(即每秒一千万亿次计算,运行 3640 天)。
如此庞大的训练任务通常无法由单个服务器完成,往往需要大量服务器作为节点,并通过高效的组网方式形成大规模的AI算力集群(Scale Out),由此才能为AI大模型训练提供强有力的支持,而这也意味着AI集群中的网络互联和交换必须具备高性能、低功耗、低时延以及高可靠性等能力,否则就会影响AI集群训练的质量和速度。

在此背景下,MEMS-OXC“重出江湖”,相比传统的电交换技术,其以高带宽、低延迟和低能耗的优势,一时间引发了业界的高度关注,特别是随着谷歌引入OXC光交换机提升AI集群性能,更使得MEMS-OXC在市场中成为了广泛讨论的热点话题。
但正所谓“透过现象看本质”,在当前的智算中心应用场景中,MEMS-OXC和自动配线架并无本质区别,在未来很长一段时间内,MEMS-OXC都很难取代传统的电交换机,或者说难以“颠覆”传统的组网架构和组网模式,其规模化落地仍然困难重重。
MEMS-OXC爆火背后的冷思考
毫无疑问,基于电交换机的组网模式在数据中心网络架构中扮演着至关重要的角色,其中以“Spine-Leaf”为代表的大二层组网模式,因其高效、可靠和易于扩展的特性,赢得了市场的一致的认可,这种组网模式的核心在于其无阻塞的交换架构,通过两层设备(Spine和Leaf)提供高效、可靠的连接,不仅能够满足大规模组网能力下的弹性扩缩、高效转发和高可靠性等需求,还能通过跨设备链路聚合技术和等价多路径(ECMP)等方式,实现多路径转发和链路快速切换,进一步提升整体网络的稳定性和性能。

但随着AI技术的不断发展,尤其是AI大模型训练对算卡的需求也在持续增长。当这种需求攀升十万卡乃至更大规模扩展时,传统的两层组网模式开始面临挑战,三层组网模式被广泛引入,通过在Spine和Leaf层增加Core层,可以更好优化网络架构,最大化提升网络性能和扩展性。
当前,由于Spine层和Core层之间需要通过光模块互联,电交换机和光模块数量的增加则会带来整体能耗的上升,此时如果Core层部署OXC光交换机实现Spine间互联,则能够一定程度上降低能耗,并提升系统的可用性。
也正因此,MEMS OXC“重出江湖”,其全称是“Optical Cross-Connect”,即指光交叉连接设备。以最典型的MEMS OXC为例:其内置两个微镜阵列,阵列A通过调整转角将入射信号偏转到阵列B对应的微镜单元,将光从入端口映射到出端口,从而实现两条路径之间的光信号交换。
由于光交换机负责在光纤间建立和断开连接,相较于传统的电交换机,高性能的光交换机能够实现更快的切换速度,对于满足智算中心中的动态流量需求可以说起到了较好的作用。

不过,如果我们“追根溯源”,其实可以发现OXC技术并不是一项“横空出世”的技术,早在2000年代初期,随着互联网流量的快速增长,研究人员其实就开始探索如何利用光网络的高带宽优势来提升数据中心和骨干网络的性能;2010年,SIGCOMM上刊登了《Helios:A Hybrid Electrical/Optical Switch Architecture for Modular Data Centers》的技术论文,进一步探索了光电混合架构的技术可行性;此后虽然OXC技术也不断有新的技术研究进展,但其商用化进程始终非常缓慢。
“转机”出现在2022年之后,随着AI大模型的出现,当年谷歌发布了OXC在云网络和自研TPU集群应用的技术论文,随后其在超大规模数据中心和人工智能计算中批量部署了OXC光交换机;2023年,NVIDIA也先后在HOT Interconnects和光网络与通信研究会及博览会(OFC)学术会议上分享了其对光电融合组网的思考,进一步推动了MEMS OXC的发展。
但MEMS OXC真的能取代电交换机在智算中心场景中的主流地位吗?如果我们深入分析之后,可以发现OXC技术仍然面临诸多技术瓶颈,相比电交换技术,其在稳定性、低时延、可用度等方面依然存在诸多的挑战,尤其是在具体的实践中,OXC技术的主要能力主要体现在灵活配线方面,而这与当下广泛使用的自动配线架并无本质区别,电交换技术无论是在规模、插损、功耗乃至成本方面均优于OXC技术。
揭开OXC技术的“三大短板”
站在当下看未来,事实上当前光交换机或者说MEMS OXC相比传统的电交换机,在技术上存在着明显的“三大短板”,其要大规模在智算网络场景中实现商用化落地,仍然面临着重重挑战,具体而言:
首先,从组网模式看,当下在AI集群组网方案中,通常2层组网不需要OXC技术,而三层无收敛组网,CLOS性能最佳;即使采用收敛组网,CLOS同样是最佳选择。
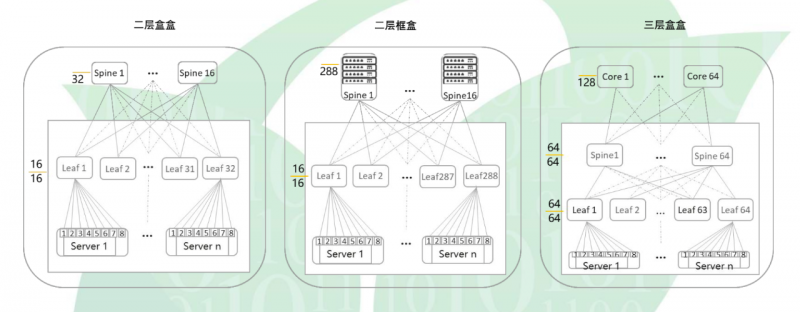
CLOS 典型物理组网
事实上,2层组网方式是应用实践较早、较普遍的网络架构,现如今依然是很多行业客户的首选。在2层组网架构中,整网设备只有两种角色,这种架构的优点是数据转发路径短,跨“Leaf”一跳可达,路径和时延具有很强的一致性,加上统一的接入方式也给上线部署和水平扩展带来了很大的便利条件。也正因此,当AI集群在4万卡以下且采用了2层组网的模式,MEMS OXC也就没有了“用武之地”。
而当AI集群超过4万卡,当前业界主要有两种组网方式,其中一种是三层无收敛组网方式,这种组网架构通常采用1:1无收敛设计,可以通过扩展网络层次提升接入的AI集群节点数量,不仅性能好、业务适应性好,同时也可以大幅提升网络的扩展能力。不仅如此,以Pod为单位进行业务部署,在适配多种业务需求、提供差异化服务等方面,三层无收敛组网方式也更具灵活性;另外一种是三层组网如采用收敛组网方式,此时跨Pod之间可引入OXC技术实现组网,虽然其提升了网络的效率和可靠性,但当下MEMS OXC的投资成本也比较高昂,而电交换机仍然在成本、性能、运维等方面具有更多的优势,因此MEMS OXC也无法显示出更高的价值。
其次,从组网距离看,2KM组网半径,如用MEMS OXC互连需要采用LR光模块,极限情况还需定制LR光模块,以满足组网距离要求,而这就需要克服OXC中常见的高插损难题。
高插损是MEMS OXC落地中难以回避的问题。通常情况下,在万卡集群的互联中中,如果采用电交换机间,其互联一般使用2km FR光模块即可,而OXC为弥补高插损难题则需使用更长距的光模块(LR),否则可能导致链路信号不稳定,引发训练中断。按目前业界最低1.5dB的差损计算,设备间互联也要使用10km LR定制光模块,由此才能够提供相对较长的传输距离,适应OXC设备之间的连接需求。但由此新的难题也就产生了,定制的LR光模块,不仅成本通常较高,交付时间也相对较长,因此MEMS OXC所带来的新技术特性,在LR光模块所面临的高插损难题上,同样并没有明显的优势。
最后,从组网能力看,MEMS OXC当前不仅难以满足AI大规模训练对稳定性和低时延的要求,同时OXC技术也不改善网络的可用度,即使采用“双归组网”方式,虽然能在一定程度上解决网络引起的断训问题,但依然不能解决接入故障后的性能降级问题。

其中,在稳定性方面,AI大模型训练环节,是整个大模型落地的重中之重,时间周期长、资源消耗大,同时“断训”也会直接影响模型的任务表现,因而对网络系统的考验也最大。但是OXC技术采用机械控制方式,同一时间只能完成一组端口间点对点转发,无法有效支撑多组流量并行转发的需求,形成性能瓶颈。与此同时,当MEMS OXC替换电交换机之后,原来标准的组网架构同样也会发生变化,导致路由协议、拥塞调度、负载均衡等策略均需要重新调整,增加了AI集群系统的“不确定性”,可能导致训练任务中断。
在低时延方面,MEMS OXC的交换时延通常在10毫秒以上,与电交换机的百纳秒时延相比,也高出了五个量级,这对于要求更低时延的AI训练任务来说,也是一个难以接受的“短板”,再加上由于整网存在端口断开和重新连接的情况,光模块、电交换机侧需要重新协商和路由收敛,又进一步延长了整网的切换和连接时间,同样也使得OXC难以满足AI大规模训练对低时延的严格要求。
在可用度方面,“双归组网”方式能够更好的解决由网络节点故障引起的中断问题。但数据也显示,基于MEMS OXC并采用“双归组网”方式,其单链路故障仍会带来约6%的性能损失,如果按10K/100K/512K集群光模块双归测算,则整个集群分别也有5%、40%以及91%的时间存在单接入链路场景,因此MEMS OXC在十万卡以上的故障中,所带来的性能降级运行时间也不容忽视。
智算场景中电交换仍“独占鳌头”
“第一性原理”是古希腊哲学家亚里士多德提出来的哲学术语,它的本意是:每个系统中都存在一个最基本的命题,它不能被违背。如果从企业需求的视角来看,“第一性原理”也代表着要回归业务的本源和本质,即技术无论如何“爆火”,客户拿到手的技术都应该是最为简单和成熟的结果。
从这个角度来说,在AI大规模训练场景中,AI集群规模越大,网络的复杂度也会越高,此时选择成熟可靠的方案且具备成本效益显著的电交换技术,才能真正化解当下网络面临的难题,我们可以从下面三个维度做进一步的观察。
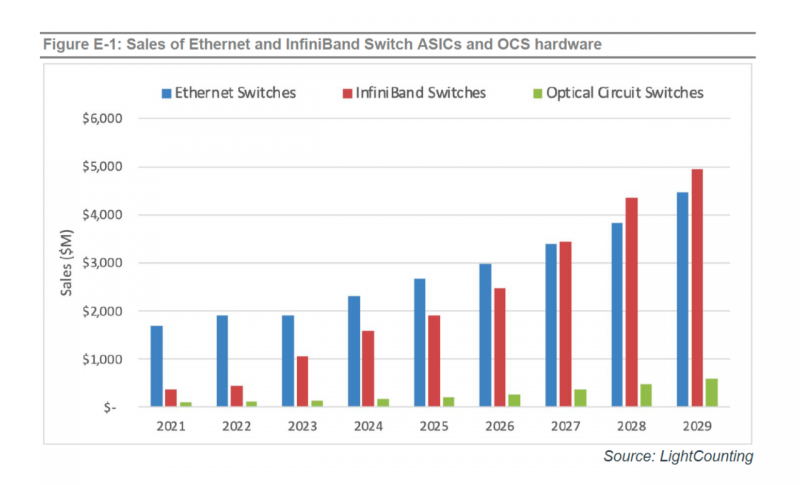
一是,从市场规模看,根据LightCounting预测,2029年OXC的全球市场空间约为5亿美元,其中大部分是谷歌OXC交换机所带来的市场增量,其产业规模仅为电交换的20分之一。因此,OXC技术仍然属于“小众”或者说“新兴”的技术,特别是在投资高昂的智算中心建设中,用户需要谨慎评估OXC技术的适用性,以避免因缺乏深入了解而成为“小白”。
二是,从落地情况看,当下很多投产的超大规模数据中心中,依然是以电交换机以及传统的组网方式为主。比如在国内,百度AI高性能网络AIPod就采用了 3 层无收敛的 CLOS 组网模式,其整个AI训练集群管理着约400台交换机、3000张网卡、10000根线缆和20000个光模块,而字节挑动的Megascale集群网络则包含10KGPU,通过一个三层类CLOS网络实现连接;在海外,Meta也基于RoCE搭建了一个由24K个GPU组成的AI集群网络,同样也通过一个三层CLOS网络实现连接,据此也不难看出,当下以电交换机以及传统的组网方式构建智算中心网络,历经了多年的市场实践和考验,证明了其依然是行业用户主流的选择“共识”。
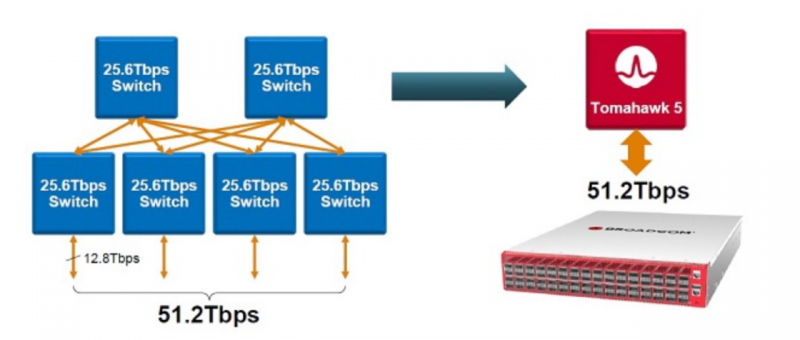
三是,从技术发展看,目前25.6Tbps的电交换机芯片早已大规模部署在国内外互联网或云计算数据中心,其能够实现两级CLOS架构384台交换机即可支持32K个CPU的部署。更为关键的是,电交换机的技术仍在进化中,其中在硬件方面,随着电交换机芯片的加速迭代,Tomahawk5的速率已高达51.2T,其单芯片支持64端口800G或128端口400G,能确保三层组网支撑50万卡集群,而预计Tomahawk6发布后可支撑百万卡集群门槛。
而在软件方面,为了解决AI参数面网络负载不均衡等问题,业界各个厂商也都在负载均衡算法这个方向加码创新,方案也呈现“百花齐放”的状态。可以预期的是,随着电交换机的持续的技术迭代,都会有助于增强智算中心网络的先进性和可靠性,进一步提升用户的投资回报率。
客观地说,用户的眼睛始终是雪亮的,MEMS OXC虽然看起来很美好,但在智算中心场景中,实践已证明了OXC技术并非未来的技术方向和演进趋势,而基于电交换技术和传统组网方案仍然在市场中占据着主导地位,且优势尽显。也正因此,对于当下众多的客户而言,MEMS OXC越是爆火,越是需要更多的冷思考,而投资成熟且可靠的电交换技术,也必然是建设智算中心网络更为稳妥和明智的选择。
文章来源:申耀的科技观察

