12月18日,数据飞轮2.0在2024冬季火山引擎FORCE原动力大会上正式升级发布。
延续去年4月火山引擎发布的数据飞轮“以数据消费促资产建设,以数据消费助业务发展”的内核,升级后的数据飞轮2.0模式更聚焦把AI作为数智化核心竞争力,数据生产、管理、应用等环节全方位融合AI能力,让企业更便捷、更低门槛地消费数据,建设资产,实现价值。
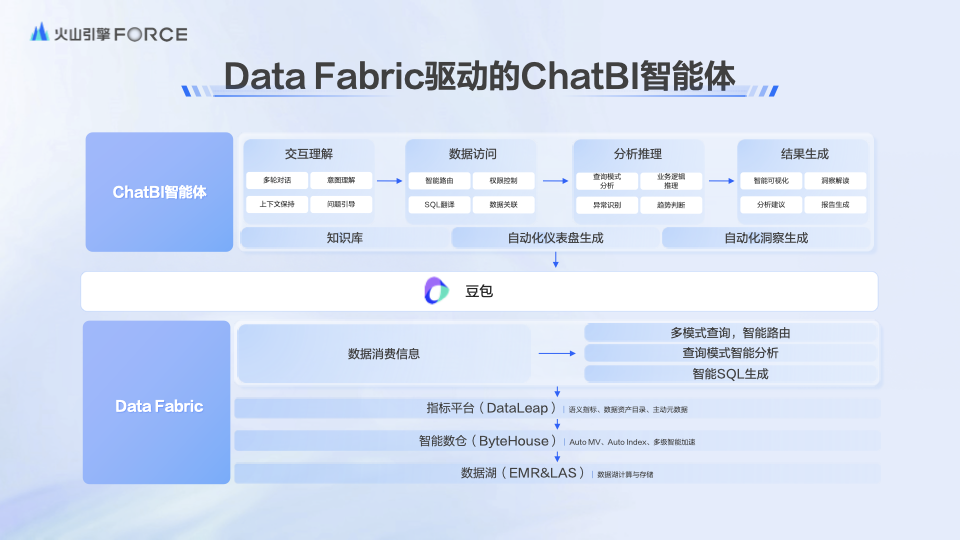
其中,聚焦企业内部员工看数、用数场景,数据飞轮2.0模式下的「Data Fabric驱动下的ChatBI智能体解决方案」将在智能数据洞察DataWind原有的自然语言问答基础上持续深钻,在重构数据生产链路的基础上,打造更贴合企业内部各业务数据应用习惯的智能体,帮助员工能更高效的获取数据、理解数据、使用数据。
定制业务专属智能体 识别企业内部用数差异
在企业内部的实际工作中,不同业务对数据的需求并不一致。
如同一份客户数据,销售部门可能关注客户数、成交金额,营销部门则更关注客户属性、人群画像、来源渠道,此外产品部门还将关注客户量级、产品/服务满意度等,数据维度、口径繁杂多样。
过去,尽管企业内部员工身份和需求不尽相同,但涉及到数据查询,通常都是在同一个底层数据库中实现——即便通过自然语言交互的形式降低了普通员工的数据查询门槛,但鉴于无法构建针对某一特定人群或团队的常用型数据查询、分析链路,每一次查询都需要重新将所有数据“跑通”一遍,因此在时效性上不能满足员工越来越高的要求。
「ChatBI智能体」将更聚焦企业内部多业务个性化数据查询、分析需求,实现业务专属「智能体」打造。
在企业内部,同一个员工往往拥有多个数据集的查询、分析权限,在不同需求环境的操作下,数据口径有可能出现不一致情况,在追溯和沟通数据口径的过程中,容易给上游数据生产部门带来比较大的解释成本压力。
针对这一问题,智能体可以通过更加聚焦员工所在的业务及用数特性加以解决。一方面,通过在智能体中指定官方数据集,先保证员工进行数据消费的口径一致性,提前避免跨数据集查询导致的口径“割裂”;另一方面,智能体还支持配置推荐问题和Prompt(提示),能够为员工提供围绕数据查询和分析的针对性服务,满足员工用数需求。
此外,「ChatBI智能体」还能够结合业务团队的使用场景,关闭无效字段、精炼语义模型,并提供“语义模型配置”,帮助业务团队能够依据实际使用需求,自定义输入大模型字段,实现真正贴合业务需要的大模型能力部署、提高大模型学习效率。
值得一提的是,「ChatBI智能体」还能在使用过程中持续深钻业务、洞察业务特征,实现相似业务数据集的规整,不断优化明确适用场景,并可支持对业务常用词、同义词进行收集和维护,在让大模型应用更加贴合业务需求的基础上,把“人”能从基础性工作上解放出来,在更核心的“事”上发挥更大价值。
数据生产实现NoETL 全方位降低数据成本
当业务能够通过「ChatBI智能体」更迅速更高频地进行数据消费后,新的挑战也在产生:
大量重复的数据建设、难以统一的数据口径,以及不断攀升的维护成本。
为了能够帮助企业快速应对这些难题,全方位降低数据成本,数据飞轮2.0模式下的「Data Fabric」完全重构了数据生产链路,通过逻辑模型取代传统物理模型,让数据生产关系变得更加灵活。
通俗来讲,可以把「Data Fabric」理解为一种架构和技术框架,它能将企业中分散、孤立的数据资源,集成到一个统一、灵活和智能的数据管理平台中。
这个过程的重点在于实现物理层和逻辑层的分离,让指标开发过程更专注于业务逻辑本身,可以拆解为三个方面:
首先,数据不再以固定的物理表形式存在,而是通过逻辑模型定义表之间的关联关系;
其次,系统能够基于定义的基数关系(一对多、多对多等)自动匹配合适的Join方式;
最后,基础指标和派生指标构建了完整的指标体系,支持灵活的数据分析。
基于这三方面的能力,「Data Fabric」得以真正实现NoETL(No Extract, Transform, Load),并可结合业务实际的数据消费情况不断优化包括引擎选择、物化视图在内的物理层实现;同时,简化指标开发、提升元数据质量、优化查询性能、降低存储成本并大幅度节约开发运维人力,助力企业从“数据丰富”转向“数据驱动”。
在数据飞轮2.0模式推行的「Data Fabric驱动下的ChatBI智能体解决方案」中,ChatBI智能体能够和Data Fabric一起帮助企业建立完整的智能数据服务体系:
Data Fabric通过语义层和数据模型的整合,重构了数据生产关系,在显著降低数据存储和计算成本的基础上,让数据服务变得更加敏捷;而ChatBI智能体则能更贴合业务个性化需求,通过交互理解、数据访问、分析推理和结果生成四大模块,极大提升业务员工的数据生产力,让数据消费变得更加简单直接。
数据显示,这套方案在字节跳动内部已经覆盖超过200个分析场景,每天处理超过10万次分析请求,平均分析时间降低了 80%;同时,数据开发和运维成本也大幅下降。
目前,为了让数据飞轮2.0所涌现的AI能力与方案能更快的在企业中落地,火山引擎也推出了数据飞轮2.0加速计划,一方面针对数据应用类的AI功能提供了3个月免费试用,让更多企业可以无成本地去拥抱AI创新带来的普惠数据消费;另一方面,他们也为想要进一步探索Data+AI场景的企业提供了3个月周期的项目制一站式陪伴,涵盖企业大模型数据应用方案规划、企业 Data+AI 能力培育、业务陪跑等多个方面,确保企业成功构建并高效运行数据飞轮 2.0。

