12月19日,智源研究院发布国内外100余个,开源和商业闭源的大模型综合及专项评测结果。“大语言模型评测能力榜单”中,豆包通用模型pro(Doubao-pro-32k-preview),在主观评测中排名第一。
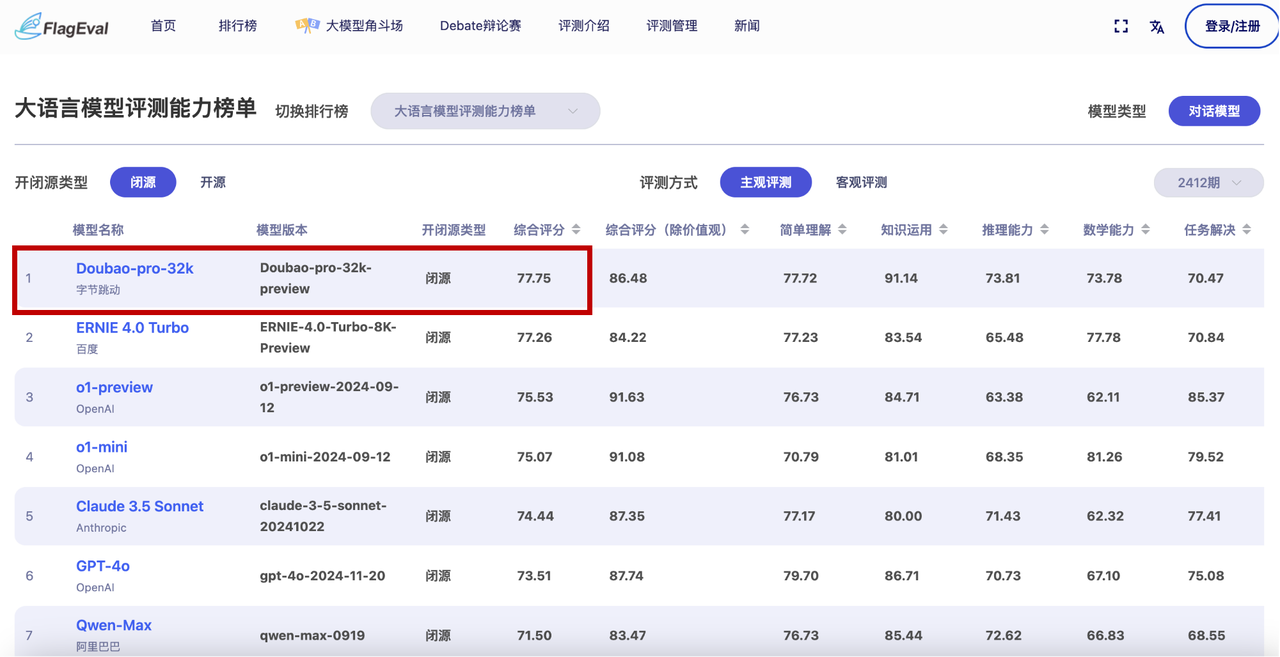
智源研究院 FlagEval 大语言模型评测能力榜单-主观评测
“多模态模型评测榜单”中,豆包·视觉理解模型(Doubao-Pro-Vision-32k-241028)。在视觉语言模型中排名第二,仅次于GPT-4o,是得分最高的国产大模型。
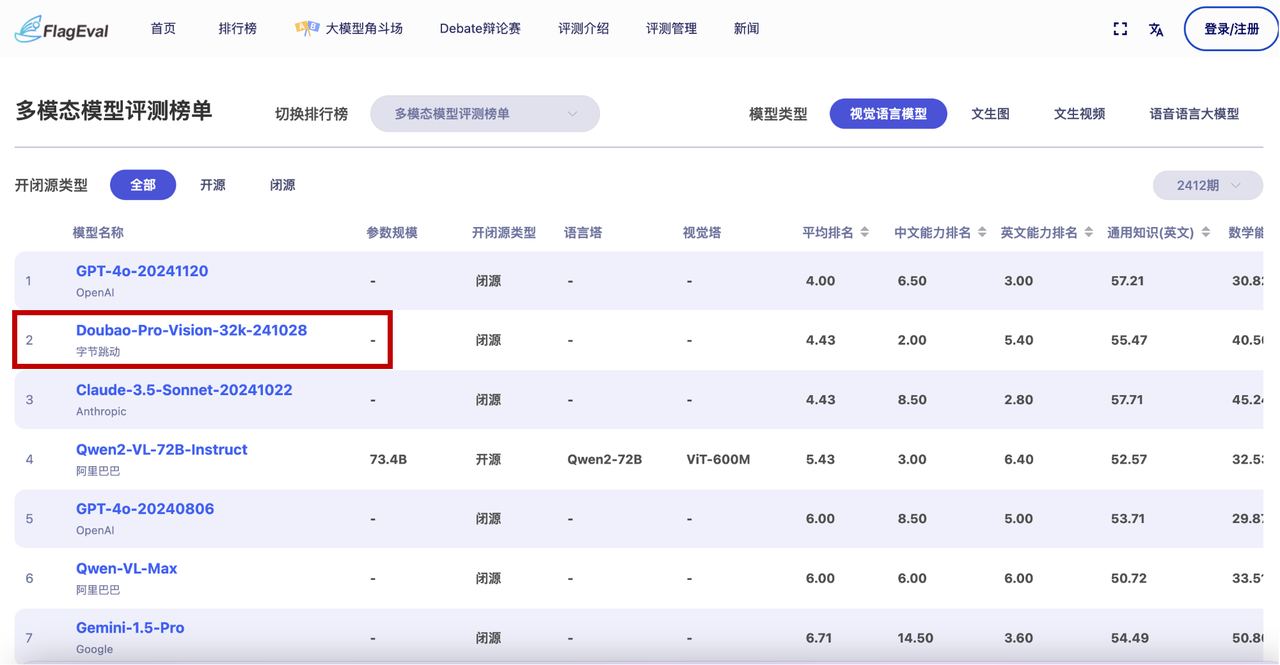
智源研究院 FlagEval 多模态模型评测榜单-视觉语言模型
“FlagEval大模型角斗场榜单”中,豆包通用模型pro(Doubao-pro-32k-240828)。
在大语言模型榜单中位居第一梯队,评分排名第二,仅次于OpenAI的o1-mini,是得分最高的国产大模型。
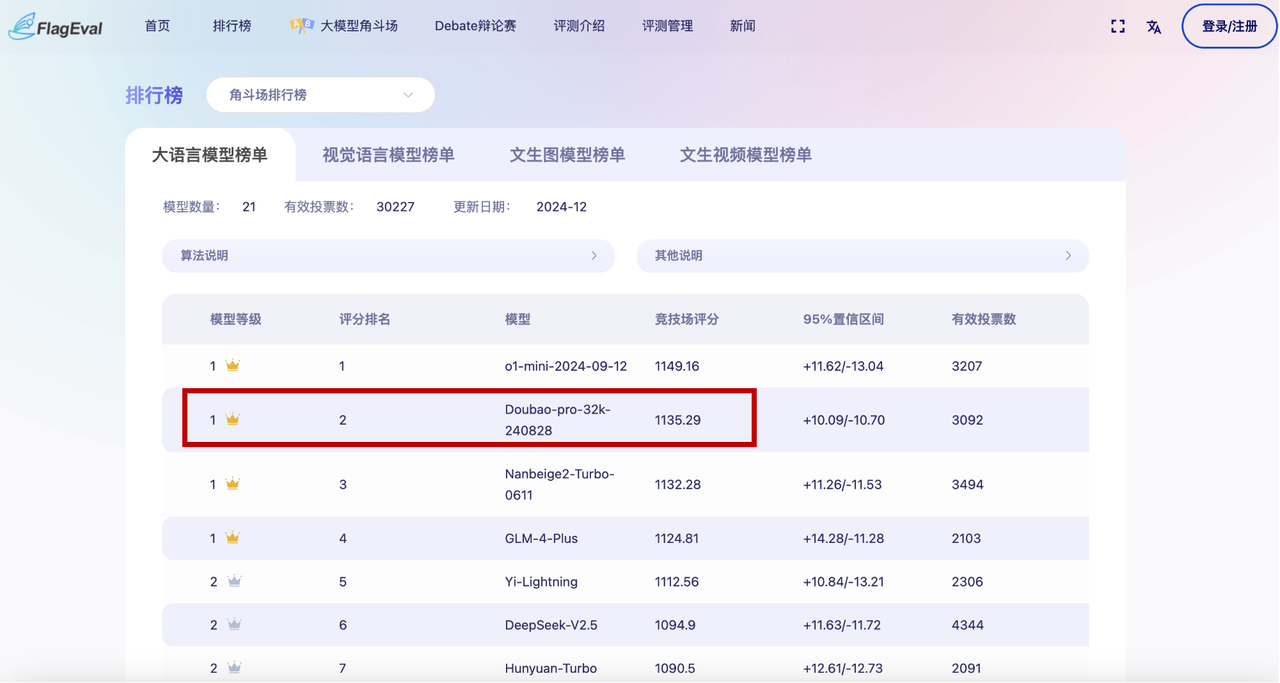
智源研究院 FlagEval 大模型角斗场榜单-大语言模型榜单
据智源研究院介绍,大模型评测平台FlagEval目前已覆盖全球800多个开闭源模型,在评测方法与工具上联合了全国10余家高校和机构合作共建。此次公布的榜单中,大语言模型主观评测重点考察的是模型的中文能力,多模态模型评测榜单视觉语言模型主要考察的是模型在图文理解、长尾视觉知识、文字识别以及复杂图文数据分析能力;FlagEval大模型角斗场则是向用户开放的模型对战评测服务,反映了用户对模型的偏好。
大使用量才能打磨出更好的模型。刚刚结束的2024火山引擎冬季FORCE原动力大会公布了豆包大模型最新进展——豆包大模型12月日均tokens使用量超过4万亿,较5月发布时期增长超过33倍,在不同应用场景中调用量快速增长。
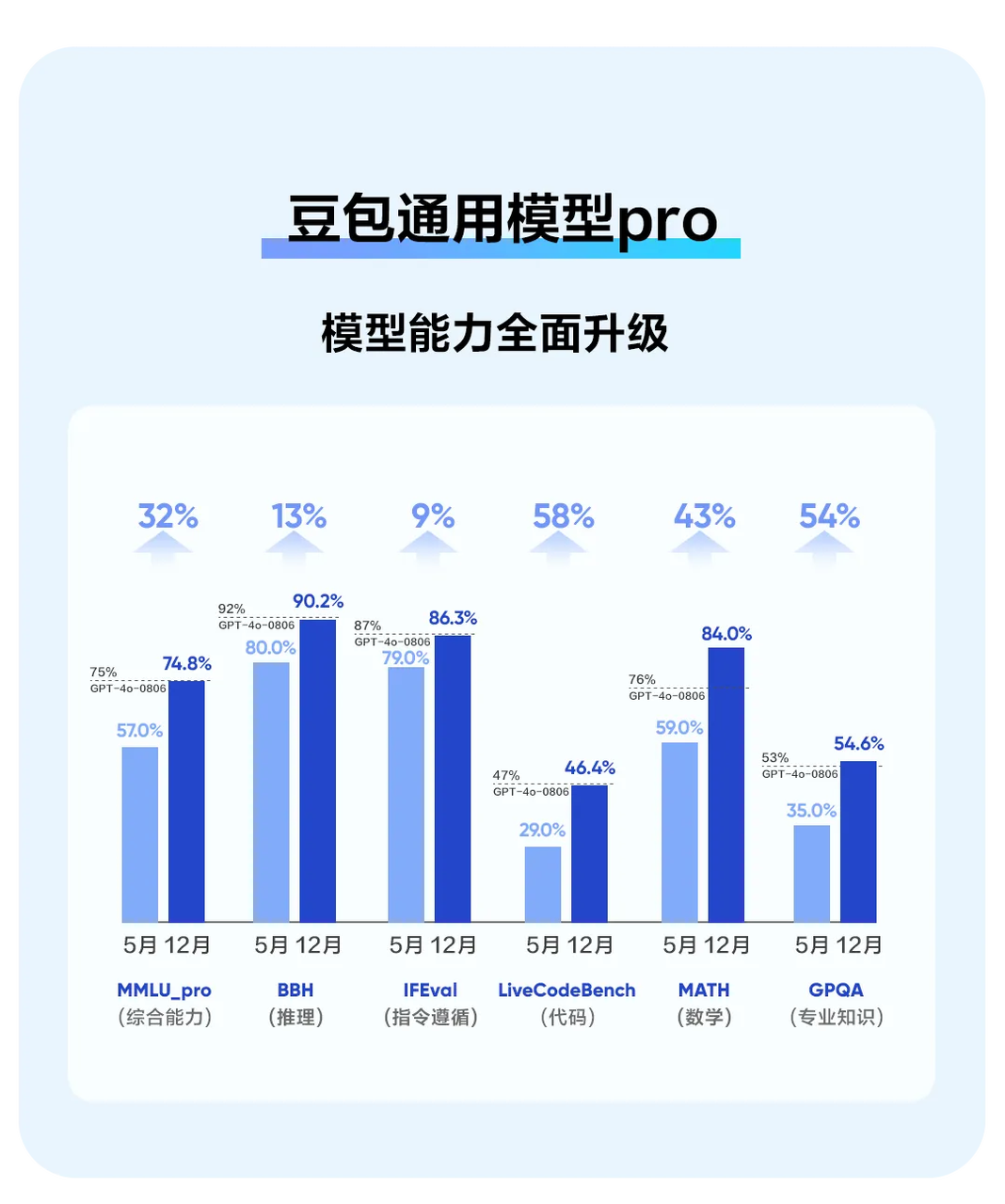
使用量和应用场景的提升,也让豆包大模型迎来了全新的升级。其中在“大语言模型评测能力榜单”的主观评测中排名第一的豆包通用模型pro完成新版本迭代,综合处理能力较5月发布时提升了32%,在推理上提升13%,在指令遵循上提升9%,在代码上提升58%,在数学上提升43%,在专业知识领域能力提升54%。
在“多模态模型评测榜单”的视觉语言模型中,得分国内最高的豆包·视觉理解模型也在FORCE原动力大会上正式对外发布。豆包·视觉理解模型可以理解用户所输入的文本和图片相关的信息,并给出准确的回答。通过更强的内容识别能力、更强的理解和推理能力、更细腻的视觉描述能力,豆包·视觉理解模型极大地拓宽了大模型场景边界,基于对真实世界的信息处理,可以更好的辅助人类完成复杂的任务。
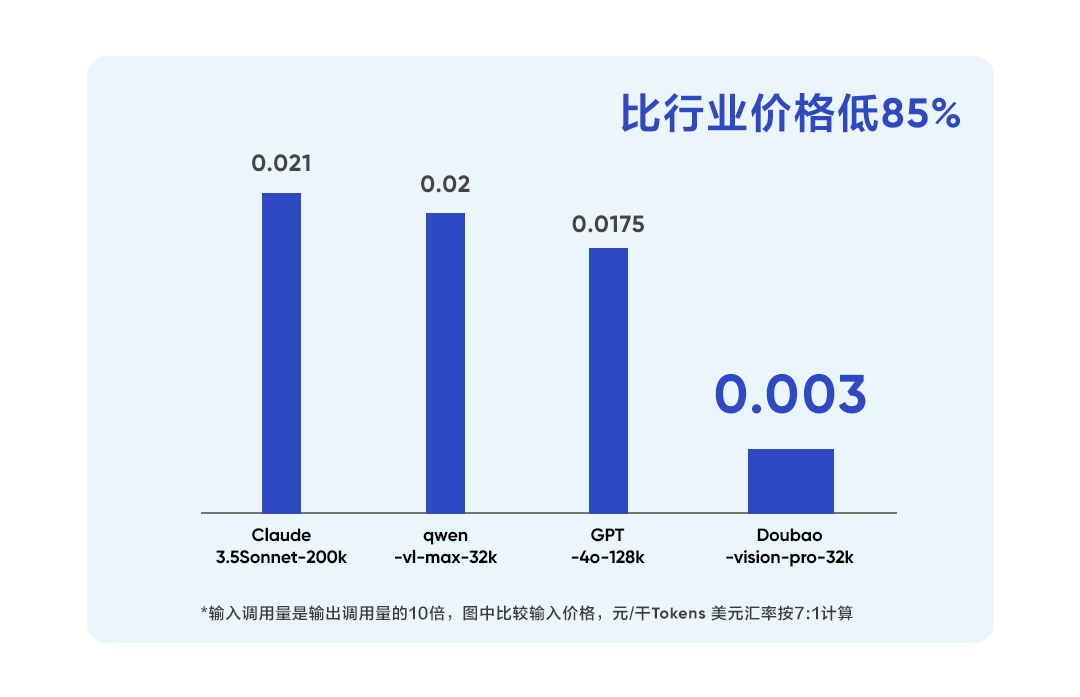
豆包·视觉理解模型在教育、旅游、电商等场景有着非常广泛的应用。为了更好地帮助企业开拓大模型的创新应用场景,豆包·视觉理解模型的价格为每千tokens 0.003元,比行业平均价格降低85%,相当于一块钱可以处理284张720P图片,让企业和开发者用好视觉理解模型,找到更多创新场景。
从能力升级到模态丰富,火山引擎将持续拓展豆包大模型的能力边界及应用场景,加速推动AI大模型应用的普及与落地,为更多企业智能化升级提供有力支撑。

