传统LoRA微调千亿模型的成本高达数百万,这让高校、中小型实验室、初创公司甚至个人开发者难以参与。而趋境科技KTransformers与LLaMA-Factory的深度集成,彻底改变了这一现状,为大模型微调提供了低成本、高效率的新选择。
该方案支持用户使用 LoRA 等轻量级微调方法,在极少量 GPU 资源下完成模型定制。经实测,仅占用约 41GB 显存,配合 2T 内存,就能实现 46.55 token/s 的微调吞吐量。对于开发者而言,操作流程也十分简便:只需同时安装KTransformers与LLaMA-Factory环境,配置好Kimi-K2的yaml文件并运行,即可启动微调任务。更关键的是,这是目前在消费级显卡上实现微调超大参数MoE模型的唯一可行方案。
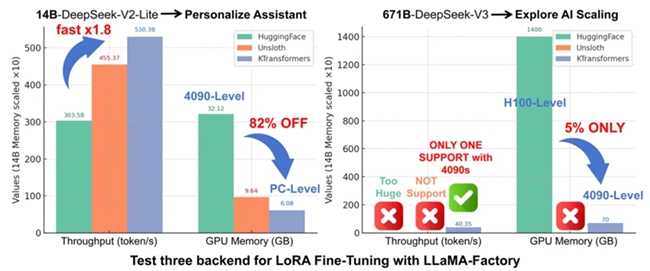
在性能对比测试中,KTransformers微调方案优势显著。在较小规模的MoE模型(DeepSeek-14B)测试中,其吞吐速度超过传统方案1.8倍,显存占用较传统方案降低 82%。传统方案多依赖H100等高端 GPU,而KTransformers可支持4090级消费级显卡,大幅降低了硬件门槛。这一方案让创新门槛显著降低,学术研发领域能尝试更多样化的想法,企业应用层面可针对自身需求快速微调出定制化模型,且成本和周期大幅缩减,产品迭代更灵活高效

