伴随企业核心业务持续向云原生架构演进,数据库正从传统本地部署模式加速迈向存算分离架构。GaiaDB作为百度智能云自研云原生数据库,采用存算分离设计,实现计算与存储解耦,在提供更高弹性与吞吐能力的同时,也对复杂查询性能提出了更高要求。GaiaDB支持大容量、高性能、高弹性场景,并兼容MySQL生态。
相比传统本地磁盘,存算分离架构下数据页读写通过远程RPC完成,呈现出“高延迟、高带宽”的特点:单次IO延迟由数十微秒提升至百微秒以上,但整体并发吞吐能力远高于本地磁盘。随着查询规模增加,大量同步远程IO容易成为影响查询性能的重要因素。
针对这一挑战,GaiaDB推出预读加速能力。
通过提前预测后续需要访问的数据页,并异步并行加载到内存,将原本同步等待的数据访问过程转变为主动准备,实现复杂查询性能大幅提升。在典型业务场景下,可实现5~20倍性能提升,加速后性能与本地盘持平甚至超出数倍。
一句话概括,查询还没开始,数据已经提前就位。
究竟哪些场景收益最明显?
预读加速主要适用于存在大量同步远程IO的查询场景,通常扫描页数量越多、缓存命中率越低,收益越明显。典型业务场景包括以下几个:
查询历史或冷数据,数据写入后长期未访问,已从内存中淘汰。
例如:查询用户3个月前订单记录;拉取去年的操作日志。
大范围时间区间扫描,WHERE条件跨越较长时间范围,需要扫描大量索引页。
例如:create_time BETWEEN '2025-01-01' AND '2025-04-01'
深度分页,翻页位置较深时需要扫描并跳过大量数据。
例如:ORDER BY id DESC LIMIT 100000,20
二级索引命中大量数据后回表,通过非主键索引匹配大量记录后,需要逐行回聚簇索引获取完整数据。
例如:WHERE status=0 AND type=1命中上万行时,会产生大量随机访问。
低频大表报表与统计查询,后台跑批任务。由于访问频率低,数据大概率不在缓存中。
例如每日凌晨对账汇总;运营数据导出等。
新实例启动后的首批查询,实例启动或主备切换后,Buffer Pool为空,所有访问均为冷读。
这些场景虽然表现形式各不相同,但背后往往有同一个问题:同步IO等待时间过长。
所以核心优化策略应该是提前准备数据,而不是等待数据。
对此百度智能云GaiaDB预读加速基于B+树逻辑结构,提前预测后续访问的数据页并异步并行预取至内存,消除逐页同步IO等待,整体覆盖两类核心查询路径,例如主索引顺序扫描以及二级索引回表。
B+树逻辑预读到底是咋回事儿?
B+树逻辑预读适用于顺序扫描索引的业务场景,例如大范围时间区间覆盖查询、报表分析以及数据导出等。
过去这类查询往往需要持续扫描大量索引页,一个报表可能耗时几十秒,复杂场景甚至需要两分钟以上;开启索引逻辑预读后,原本分钟级的查询可缩短至秒级返回,实现数倍性能提升。
其核心思路可以理解为:先看目录,再翻内容。
当数据库执行大范围顺序扫描时,逻辑预读不会等当前页面读取完成后再访问下一页,而是像翻书时先看目录一样,提前查看索引上层节点,获取接下来即将访问的数据页列表,再一次性批量加载至内存,从而大幅减少扫描过程中的等待时间。
整个索引逻辑预读流程由4个核心模块协同完成,按照“触发—决策—执行—缓存”的链路逐层推进。
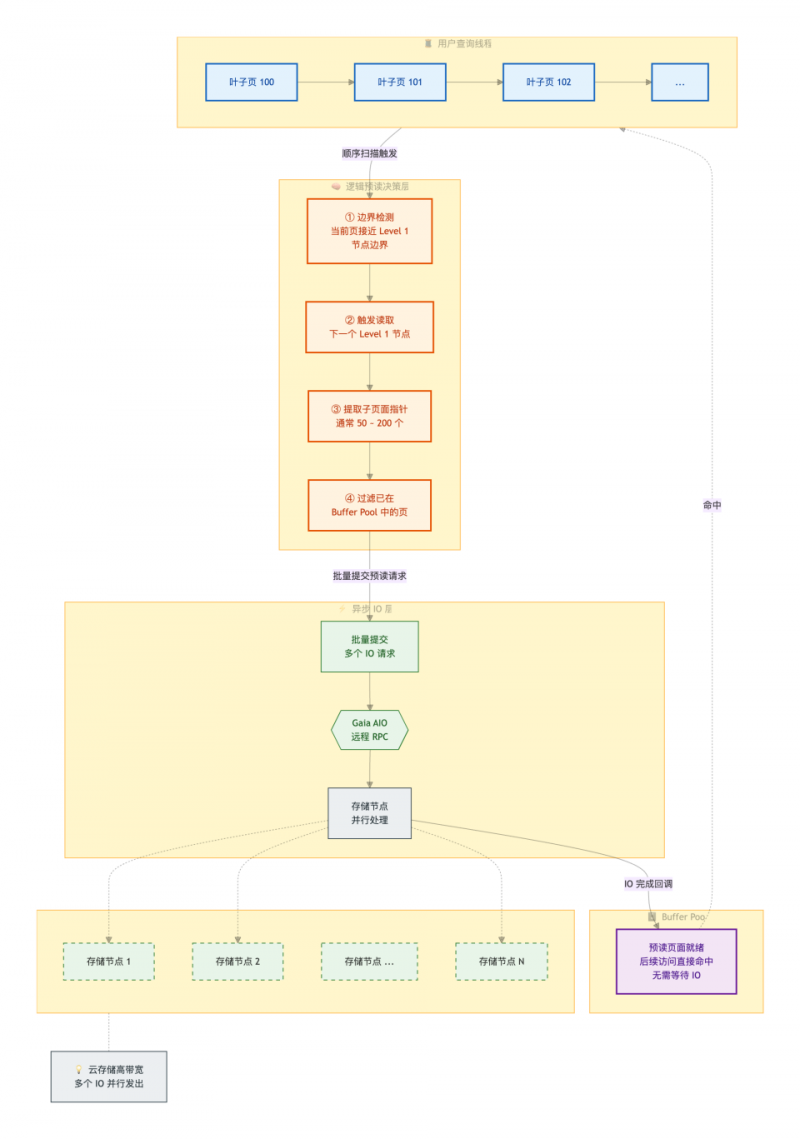
逻辑预读流程图
模块1:用户查询线程:负责执行查询,触发索引顺序扫描,并识别预读边界。
主要执行流程包括:
1.对数据库索引叶子页执行顺序扫描;
2.按照 Page100 → Page101 → Page102 → …… 顺序持续推进;
3.在扫描过程中持续检测预读边界,并将触发信号传递至逻辑预读决策层。
这一阶段负责正常查询执行,同时也是整个预读机制的触发入口。
模块2:逻辑预读决策层:负责判断预读时机、筛选待预读页面,并生成批量任务。
主要执行流程包括:
边界条件检测:判断当前扫描位置是否接近Level-1索引节点边界。
主动触发预读:满足触发条件后,主动读取下一个Level-1索引节点。
解析页面信息:从Level-1节点中提取全部子页面指针。
缓存过滤:过滤已经存在于Buffer Pool中的页面,仅保留未缓存页面。
生成预读任务:输出批量待预读页面列表,并提交至异步IO层。
这一阶段负责完成从“发现下一批数据”到“确定真正需要读取哪些数据”的全过程。
模块3:异步IO层:基于Gaia AIO框架,通过远程RPC并行请求数据,充分利用云存储高带宽能力。
主要执行流程包括:
1.基于Gaia AIO框架发起远程RPC调用;
2.将批量预读请求下发至存储节点,实现多IO并行处理;
3.利用云存储高带宽特性,最大化整体IO吞吐效率;
4.IO完成后,通过回调机制通知Buffer Pool完成页面加载。
这一阶段负责把原本串行执行的数据读取过程改造成并行执行。
模块4:Buffer Pool(缓冲池):负责缓存预读页面,为用户查询提供高速访问能力
主要执行流程包括:
1.接收异步IO层完成加载的数据页;
2.将页面写入Buffer Pool,并标记为可用状态;
3.后续用户线程访问该页面时,可直接命中缓存,无需等待磁盘IO。
这一阶段相当于提前完成“数据备货”。
当真正查询到来时,数据已经准备完成,实现从“查询等数据”到“数据等查询”的转变。整个过程中,原本“扫描一页、等待一次”的串行模式,被重构为“边扫描、边预取、边缓存”的并行机制。在数据量越大、扫描范围越广的场景下,预读对IO等待的隐藏效果越明显,加速收益也会进一步放大。GaiaDB采用存算分离架构并持续优化复杂查询性能。
二级索引回表预读又是什么机制?
二级索引回表预读适用于二级索引扫描后需要回表查询聚簇索引获取完整行数据的场景,例如按条件筛选+分页的列表查询,或通过索引字段过滤后再获取完整数据的业务SQL。在这类场景下,查询通常需要频繁执行回表操作,随着命中记录数量增加,同步IO等待会逐渐成为主要性能瓶颈。开启预读能力后,可实现数倍甚至数十倍性能提升。
其核心思路是在主线程逐行执行回表的同时,提前扫描后续二级索引记录,预测后续回表目标页面,并批量异步预读至Buffer Pool。当主线程真正执行回表时,目标页面已提前加载至内存,从而消除同步IO等待。
与索引逻辑预读不同,两者关注对象存在明显差异:索引逻辑预读关注的是当前索引自身后续即将访问的叶子页;二级索引回表预读关注的是聚簇索引中回表目标对应的叶子页。
简单来说,一个提前准备“下一批要扫描的数据”,另一个提前准备“下一批要回表的数据”。
二级索引查询异步预读整体涉及4个核心模块,其中模块3和模块4与索引逻辑预读保持一致。整个流程由查询线程、预读决策以及异步IO协同完成。
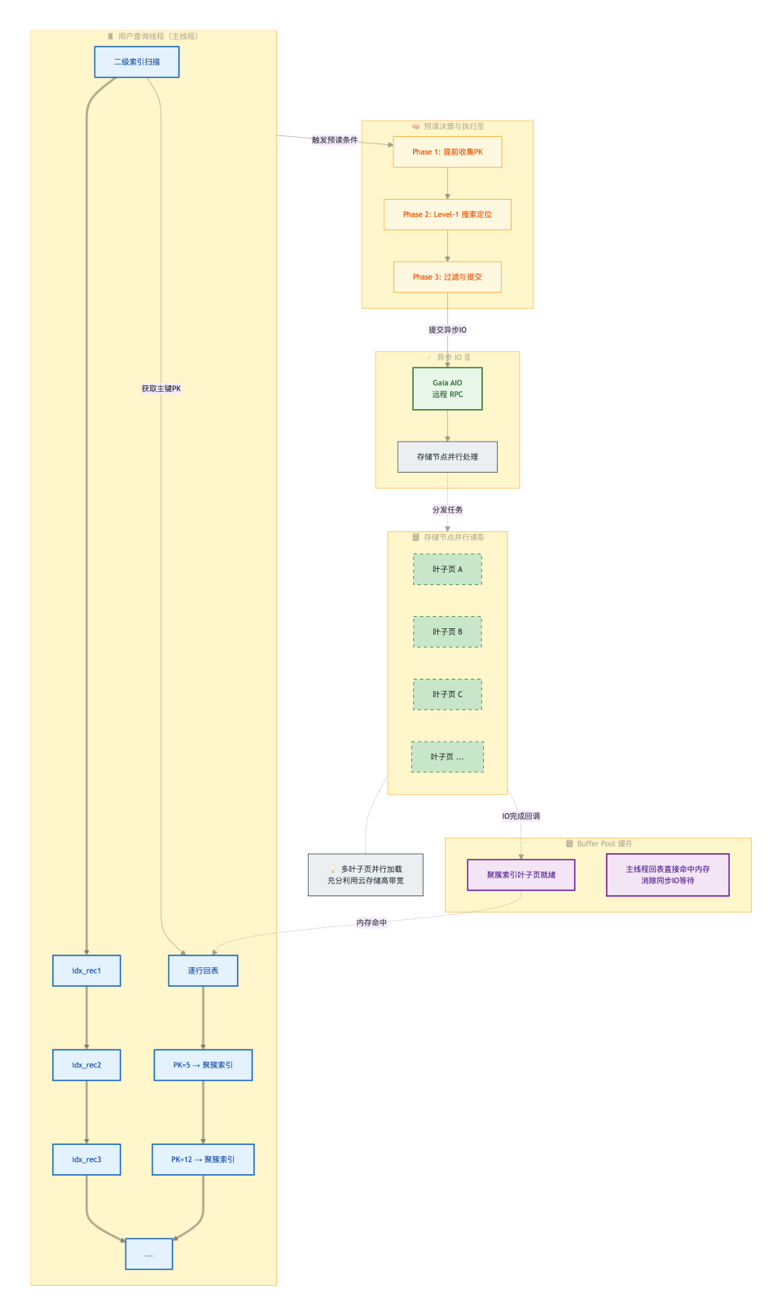
二级索引回表预读流程图
模块1:用户查询线程
核心职责: 执行用户查询,完成二级索引扫描与逐行回表,并负责触发预读条件检测。
关键执行流程包括:
顺序扫描二级索引记录,按照 idx_rec1 → idx_rec2 → idx_rec3 → … 持续推进; 根据二级索引记录中携带的主键信息,逐行执行回表,通过主键查询聚簇索引数据; 在扫描过程中持续检测预读触发条件,当达到预设阈值后,向预读决策层发送触发信号。
这一阶段主要负责“正常查询”,同时承担预读触发入口角色。
模块2:预读决策与执行层
核心职责: 完成预读流程调度、页面解析和目标筛选,是二级索引异步预读的核心控制单元。
主要执行流程包括:
1.提前扫描二级索引记录,批量收集后续多条记录对应的主键值;
2.根据主键在聚簇索引中执行Level-1搜索,解析并定位目标叶子页页号;
3.进行缓存过滤,自动剔除已存在于Buffer Pool中的常驻页面;
4.汇总缺失页面列表,并整理为批量预读任务提交至异步IO层。
这一阶段负责完成从“记录”到“页面”的映射和筛选,决定真正需要预取哪些数据。
优化效果:典型场景最高提速18倍
为了验证预读加速效果,在统一机器规格和资源配置下,对真实线上业务SQL进行了测试,并排除了热数据影响。
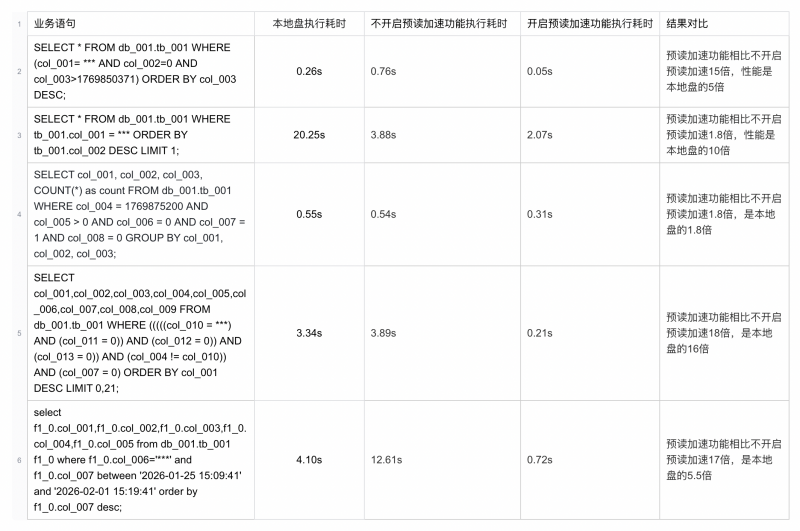
整体来看,预读加速能力相比原始版本实现数倍至数十倍提升;随着同步读取页面数量持续增加,性能优势还会进一步扩大。
线上真实案例验证
目前,预读加速能力已在部分生产实例上线,效果显著,例如:
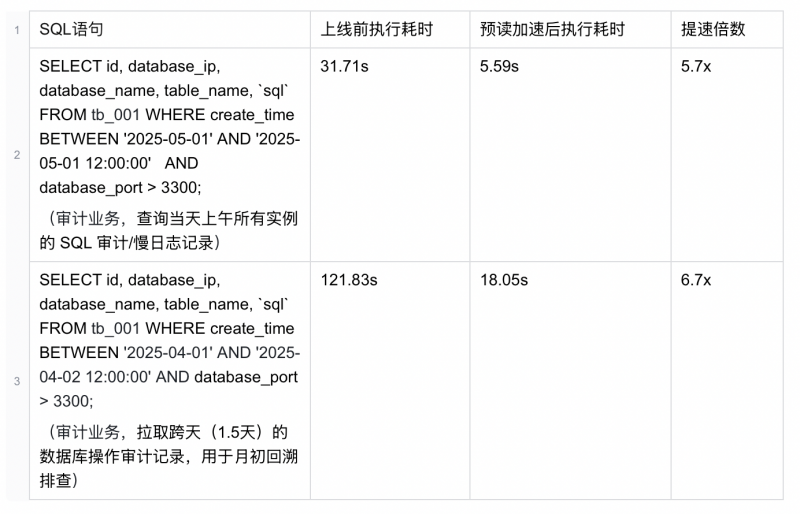
在上述场景中,预读加速将查询时间缩短至原来的约1/6。随着扫描数据量增加,异步并行预读对IO等待的隐藏效果将更加明显,加速收益也会持续放大。
预读加速并非简单提高读取速度,而是改变数据访问方式。通过“预测+异步+并行”机制,将原本串行等待的数据访问过程升级为主动准备,让“查询等数据”变成“数据等查询”。在冷数据、大范围扫描、深分页以及复杂回表等典型场景下,实现5~20倍性能提升,进一步释放云原生数据库性能潜力。

