在2024年12月7日的StarRocks Summit 2024上,腾讯游戏数据团队孵化打造的数据品牌“Deltaverse”正式亮相,并发布了品牌旗下首个数据产品——大数据时代的智能数据助手“UData”。在峰会现场,腾讯游戏数据的技术负责人、资深专家工程师刘岩发表了主题为《AI时代的湖仓数据体系建设》的演讲,分享了腾讯游戏在「AI+湖仓」上的实践经验,以及UData如何帮助腾讯游戏业务提升数据工作效率。

腾讯游戏数据负责人刘岩在StarRocks Summit发表主题演讲
作为一款问答式智能AI数据助手,UData基于大语言模型技术和湖仓一体架构打造,以新一代AI数据资产体系为支撑,资产能被AI理解和使用,能够提升业务需求到数据交付的准确率,为用户提供自然语言交互方式查询、探索、分析和可视化数据的便捷体验。
据刘岩介绍,UData已被应用于腾讯游戏内部超过80个业务,SQL代码编写效率提高了300%。在人们最关心的交付准确率方面,UData的一次性准确率达到89%,已满足实际业务场景需求。
UData产品界面
“腾讯游戏现存业务每年有数万个数据挖掘和数据提取类需求,相比BI场景,数据挖掘需要面对数万甚至数十万张表,这些表能够让AI理解,并且做到人类水平的准确率,才能满足实际业务场景需求。”刘岩表示:“我们一直在探索如何更好地让AI能力为数据工作赋能,让AI真正被应用到实际业务场景中,让Data+AI成为企业的核心竞争力。UData是腾讯游戏数据团队内部的最佳实践,解决了构建"Data+AI"体系的关键问题。”
提升AI交付准确率的关键:需求构造和资产建设
腾讯游戏数据团队在大量的实践和研究分析中发现,在企业实际业务场景中AI写SQL的准确率之所以不高,往往并不是大模型能力不足,而是因为两方面的原因:第一是AI对数据需求的理解有歧义;第二是AI对数据资产的理解有歧义,大模型没有获得完备的信息。
针对这两个痛点,UData的技术路线重点就放在了需求构造和资产建设这两个方向上,通过工程化的方式来提升AI的准确率。
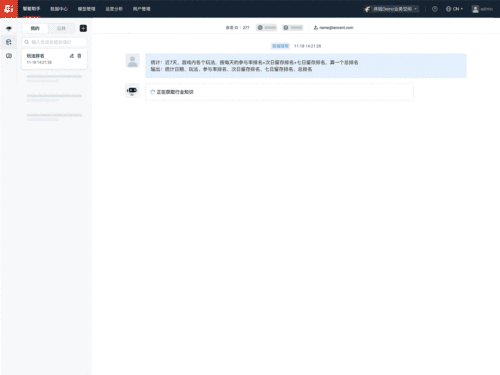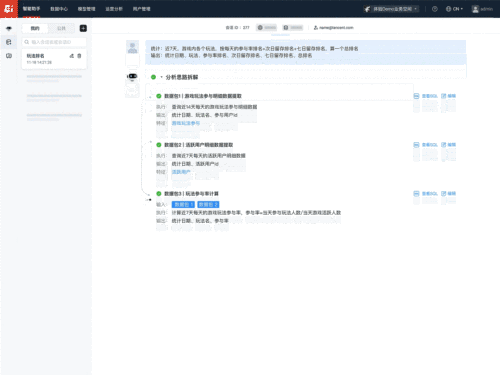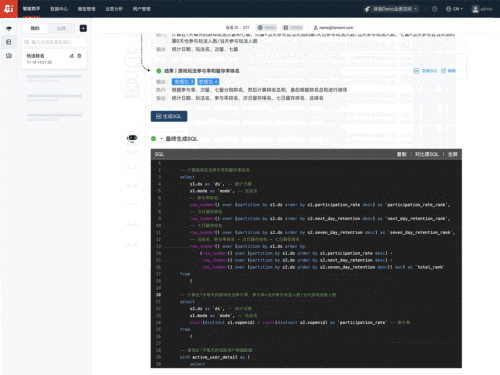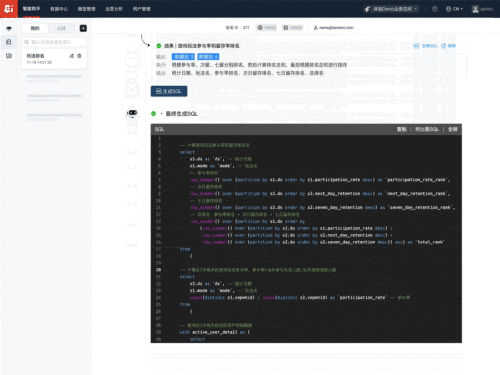
在需求构造上,首先定义AI和人都能理解的需求标准,基于定义好的需求标准,匹配需求案例和行业知识,将人提出来的需求改写成标准的需求格式,消除AI理解需求的歧义。此外,当数据需求较为复杂时,需求Agent能把复杂需求分解成简单的子需求,降低AI生成难度,通过工程化方式组合成最终结果,确保稳定可控的交付质量。
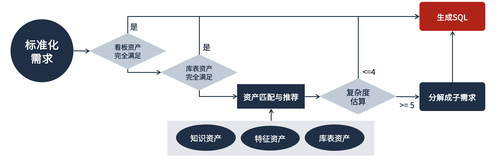
UData需求构造流程
举例来说,当用户提出需求:统计游戏内各个玩法、按照每天的参与率排名+次日留存排名+七日留存排名,算一个总排名。UData会去查询相应的游戏领域知识,将这个复杂需求分拆为4个子需求,分别计算并生成参与率、活跃用户、玩法参与率、次日和七留的SQL,最后将4个数据包SQL结果合并,生成一个最终的SQL。
在资产建设方面,为了让AI能够更好的理解和使用资产,UData打造了基于“AI驱动的数据资产体系”。传统资产体系存在缺乏非结构化标准、建设滞后于业务需求、治理成本高等问题,不能支持大语言模型实现快速准确的交付数据需求。所以基于“新一代AI数据资产”,以让AI能够理解并且正确的交付SQL实现自助交付为目标,定义语义层建模规范,包括:行业知识、指标、维度、特征、元数据等。AI通过理解语意资产,对不同的需求采用不同的资产使用策略;对于已经有指标、维度资产的需求,通过推荐已有看板满足;对于新的指标、新的维度的需求,通过特征资产让AI生成指标、维度来满足;对于缺少语意资产的需求,AI能够感知并预警,补充特征等语意资产后,实现AI资产交付。
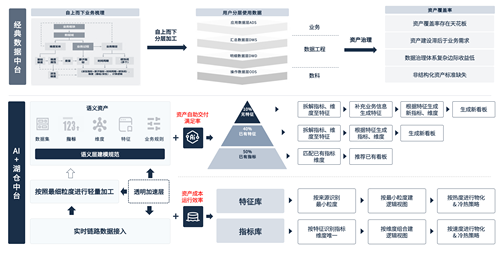
传统数据中台到新一代AI数据资产的升级
“新一代AI数据资产”能建立从业务需求、行业知识、数据结构之间的资产纽带,通过领域模型进行沉淀和推荐,确保资产能被AI理解和使用。
“稳定可控的需求构造和AI可理解的资产体系,是UData提升AI交付准确率的关键,也是UData相较于行业其他产品的差异化优势。”腾讯游戏数据技术负责人刘岩表示:“从目前腾讯游戏内部的应用情况来看,准确率已经能够稳定在89%,我们坚信这个方向是靠谱的。”
基于湖仓一体能力,实现智能动态的计算加速
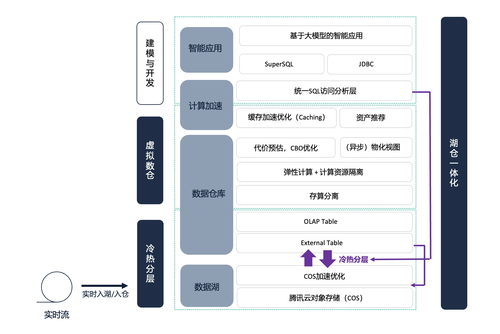
为了能够支持对实时的明细数据进行探索和分析,仅仅把SQL写对是不够的,传统的数仓架构(例如:Lambda)大量计算是T+1离线进行的,不能支持对所有的数据进行实时快速查询。为此,UData对数据底座进行了升级,采用湖仓一体的架构,通过数据实时接入、虚拟数仓、冷热分层等技术实现对实时明细数据的高效查询。同时,UData建设了一个成本效率优化引擎,围绕资产热度、执行速度、数据量级三个方向快速定位需要优化加速的资产,通过资产整合、物化视图等方式,能够让数据低成本、高效率的使用。
基于大模型能力,建设可持续优化的运营平台
以新一代AI数据资产为基础,通过通用大模型、领域模型、Agent多智体架构,AI 能力得到了更好的释放。
目前,UData能够适配包括GPT、混元在内的多种行业通用大模型。此外,针对各行各业的行业Know-How、企业知识,UData引入了“领域模型”,通过知识图谱、语义理解、检索、排序等技术,帮助大模型更好地理解数据资产。
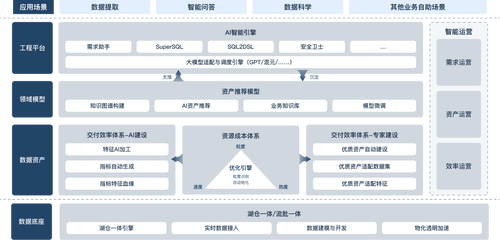
UData系统架构
在平台应用流程方面,UData使用Agent多智能体架构,打造了一个人与AI高度协同工作、可持续优化的运营平台。将一个Job(工作)分解成若干的Task(任务),在某些Task上由AI完成,某些Task人与AI协同完成(需求协同、验收协同),覆盖从业务需求到数据交付的全链路,各节点Agent可与用户实时交互,及时感知问题并进行干预和修正,确保系统的可持续优化。
AI多智能体架构
让AI重构数据工作的各个领域
UData已被应用于腾讯游戏内部超过80个业务,针对MOBA、MMORPG、战术竞技等不同品类的游戏,UData会基于具体的业务个性化需求,进行产品的持续迭代升级。
除了游戏业务之外,UData产品能力也可被用在其他行业,诸如餐饮、金融、教育等,助力传统企业实现AI数字化转型,提升数据工作效率,并通过新一代AI数据资产提升数据治理ROI,帮助企业降本增效。

AI技术在数据工作上的应用仍有巨大的潜力,腾讯游戏数据团队Deltaverse也在不断地探索,除了通过AI生成SQL以提升数据获取效率之外,我们还在进一步尝试将“AI+湖仓一体”的能力与更多工具和系统做集成,进一步探索挖掘AI的潜力,实现用AI来重构数据工作的各个领域。
对腾讯游戏数据团队Deltaverse、UData以及数据技术感兴趣的企业与合作伙伴,可以登录Deltaverse官网 www.deltaverse.net 查看更多信息,免费申请产品试用。

